Stuck with Amundsen? Here is how to migrate to OpenMetadata


And unlock Collaboration, Data Quality, Data Insights, and more!
Amundsen is one of the OSS Data Catalogs that was developed by Lyft and was open-sourced in October 2019. It quickly became popular for solving data discovery and data governance challenges. However, in recent years, Amundsen’s development and growth have slowed down considerably. Without an active community and no clear roadmap to address the emerging needs, the users of Amundsen are looking for alternatives in the OSS space.
OpenMetadata is redefining the modern metadata platform with a bold vision. We have built a centralized metadata repository based on metadata specifications and APIs from the ground up. It is the foundation for innovation with several applications, such as Discovery, Collaboration, Governance, Data Quality, and Data Insights going beyond passive Data Catalogs. Learn more about OpenMetadata’s journey so far here.
One of the frequent questions we get in our community is how can I migrate my existing Amundsen installation to OpenMetadata without losing all the metadata built over the years. In this post, we will discuss the main differences between Amundsen and OpenMetadata. We will showcase how easy it is to migrate all the knowledge stuck in Amundsen to OpenMetadata and unlock many new capabilities.
Why should you Migrate?
While Amundsen is a Data Catalog, OpenMetadata is an Active Metadata Platform with multiple applications built on top of it. Discovering the data is just the first step in a long chain of steps for any user:
Can I trust this data?
Does it fit my use case?
How are other people using it?
How can I request descriptions or tags?
How can I add a test to the tables I use to ensure data quality?
With the recent 1.0 Release, OpenMetadata comes packed with core features around Discovery, Collaboration, Governance, Data Quality, Lineage, and Data Insights. Its goal? To be the single place to answer any questions users have about data and collaborate seamlessly.
Moving your data from Amundsen into OpenMetadata means improving your Data Discovery experience, unlocking new capabilities to profile your data, creating data quality tests and alerts, and setting up an environment to allow your organization to collaborate towards better data culture.
Moreover, the foundations of OpenMetadata revolve around the following:
Metadata Schema Specifications: define a controlled vocabulary for metadata with types and constraints. Standardizing the language for metadata removes the need to reinvent the wheel when building metadata applications and opens the door for collaboration with other communities.
Metadata API Specifications: that power every aspect of the platform, from any click on the UI to the native Metadata Ingestion or Data Quality capabilities.
Architectural Simplicity: built in the open-source space from the ground up, OpenMetadata requires only three dependencies, MySQL or Postgres for storing metadata, Elasticsearch or OpenSearch for powering search queries and schedulers like Airflow, Argo, Dagster, etc., to run the ingestion connectors. With fewer well-proven dependencies, it’s easy to deploy and manage production installations.
Collaboration: Activity feeds to track all the changes on your metadata. Conversation threads to discuss these changes happening in your data. Request description/tags workflows. Create Tasks and assign them to owners of the data.
Native Data Quality: Build trust in your data by creating tests with zero-code data quality in OpenMetadata. Learn more about Native Data Quality in OpenMetadata
Data Insights: Organizations can drive the adoption of OpenMetadata by monitoring its usage and setting up company-wide KPIs. The built-in goal-setting and tracking mechanisms help proactively drive your company’s data culture. You can define the Key Performance Indicators and set goals to be achieved within a timeframe towards better documentation, ownership, and tiering.
Built on Modern Frameworks: OpenMetadata is built on top of modern frameworks, easy to operate on any public cloud or private cloud environment. You can deploy it on top of Kubernetes, Docker, or bare metal.
Ingestion Framework: OpenMetadata has built 62 connectors to bring the metadata from various sources. Users can also build their own custom connectors easily. Here is a webinar showing how to build custom connectors.
Security and Compliance: As a Metadata platform, we know how important it is to keep the data secure. That’s why we invested in security from Day 1. OpenMetadata code goes through snyk.io, and GitHub Dependabot code scanning, and every release goes through container scanning. These reports are publicly available, allowing organizations to trust and deploy the software in production.
SSO Support: OpenMetadata provides support for all the major SSO integrations. Making it easy for anyone to integrate into their company’s SSO and bring their users and offer a secure solution.
Development Velocity — OpenMetadata is built on top of modern frameworks and has a release cycle of 4–6 weeks for the major version and every two weeks for the minor version. In the past 1.5 yrs, our community delivered 45 releases. In a short time, OpenMetadata has been adopted and deployed in 100s of companies and used by 1000s of users.
Innovation — The OpenMetadata community has built many innovative features that no open-source and proprietary data catalogs can match. The Architecture and design decisions we made and our vibrant community will continue to innovate and set OpenMetadata apart from other platforms.

Merged PRs by week for the last year between Amundsen & OpenMetadata
Come for the Vision and Stay for the Execution
OpenMetadata was announced on Aug 2021 with a grand vision. We accomplished a large part of that vision with our 1.0 Release and continue to innovate and provide a roadmap of our goals by incorporating feedback and feature requests from the community.
By migrating to OpenMetadata, not only will you gain a platform that is easy to deploy, manage, secure, and packed with features, but you will also be a part of a fast-growing community executing a great vision and delivering new features with every release.
Migration Guide
Migrating any production service requires a lot of work and is often a cumbersome process. Our goal for the Amundsen migration has been to make it as simple as possible and ensure that your teams’ work is not wasted. As our guide below will show, we migrate all the documentation, ownership, and tags into OpenMetadata. All your team’s work in Amundsen will be preserved and carried to OpenMetadata.
For this example, we will migrate some sample data from Hive, Delta, and DynamoDB.
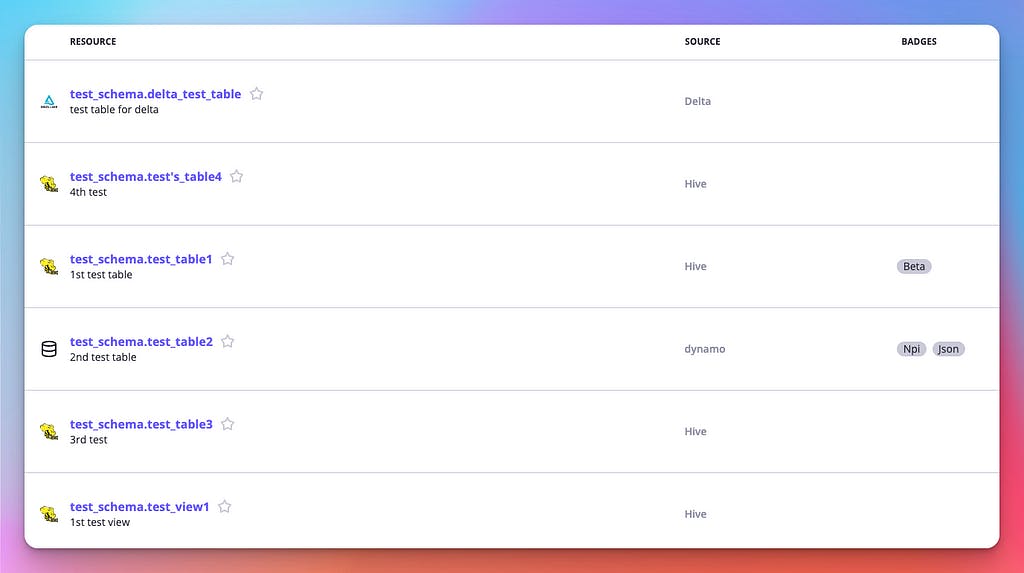
Amundsen metadata
If we look at one of the tables, we’ll see how it contains descriptions, owners, and tags:
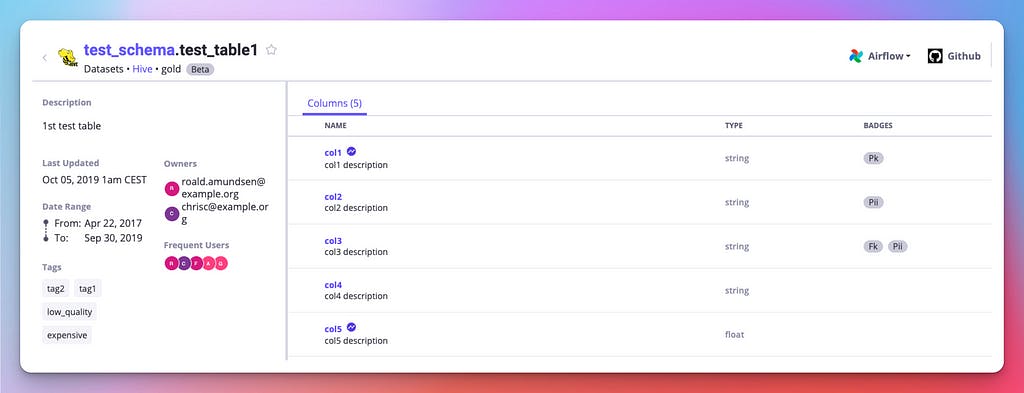
Amundsen details view
Our goal is to ensure that all of this information is preserved once you move to OpenMetadata. The deployment process is out of scope for this guide, but you will find all the necessary information here.
Step 1 — Create the Amundsen Service
A Service is an entity holding the connection information of a source we want to extract metadata. On the OpenMetadata UI, click on Settings; in the left panel, click on Metadata to add a new Service.

Create the Amundsen service
In the connection information, add the credentials to connect to the underlying Neo4J instance.

Add the connection details
Once the Test Connection is successful, follow the steps to create and deploy the ingestion workflow. Since this will be a one-time action, you can schedule it to None, and we will trigger it manually in the next step.
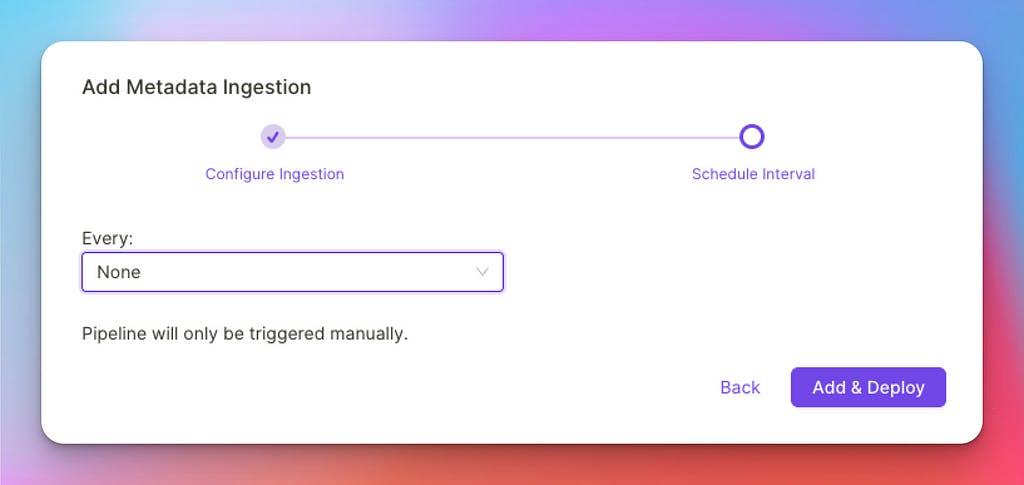
Schedule the ingestion process
Step 2 — Run the Metadata Ingestion
Navigating to the Service, you will see the control panel for your ingestion workflow. Click on the Run button and give it a few minutes until the run is Successful.
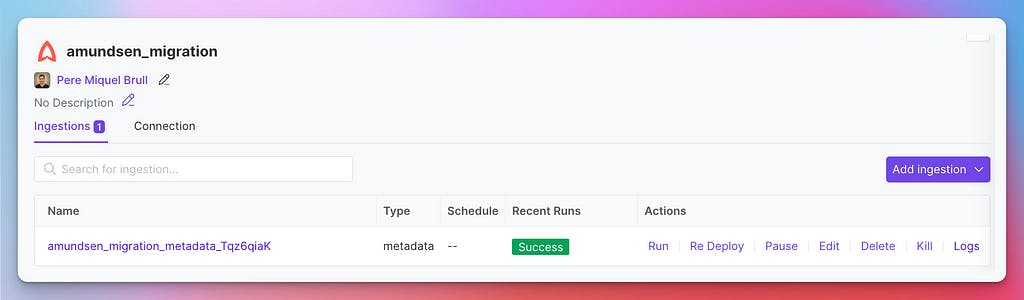
Run the Metadata ingestion
Step 3 — Explore the Metadata
Once the run is complete, we will see three new Database Services in OpenMetadata: Hive, Delta, and DynamoDB.
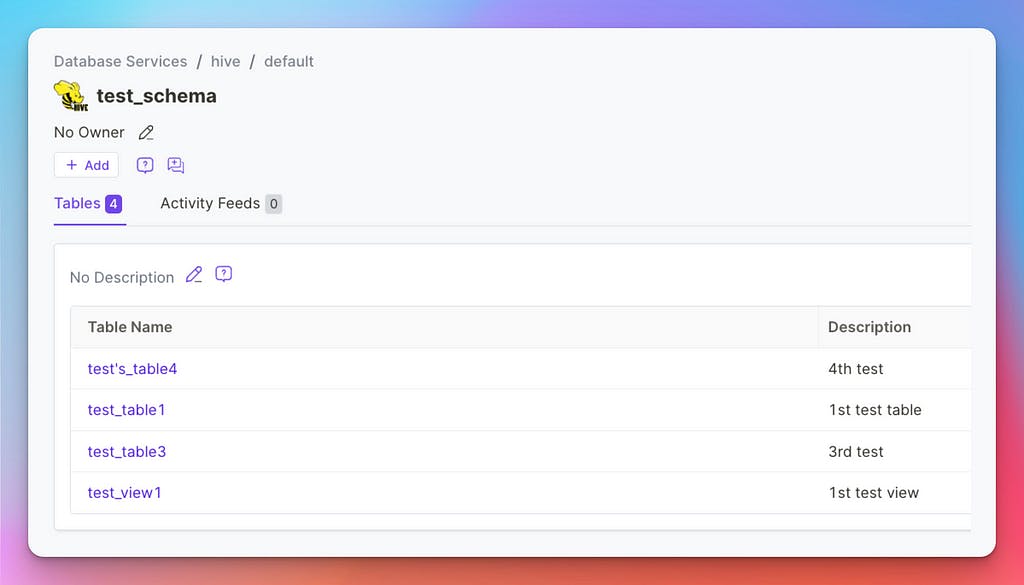
Metadata in OpenMetadata
If we inspect the metadata we got from Hive, all the Amundsen tables will be inside, and we will be able to view the same information in the new platform.
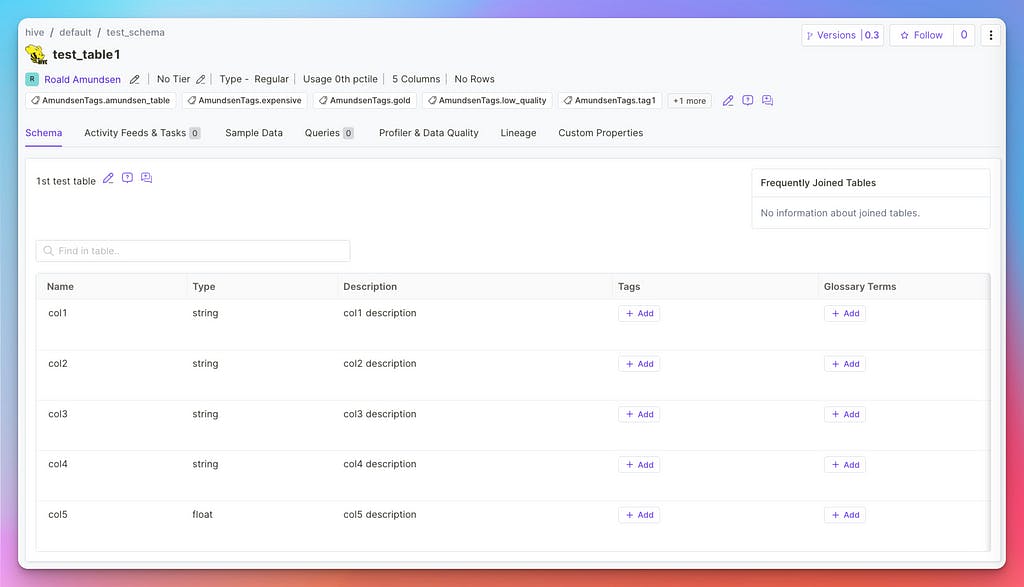
Hive details in OpenMetadata
For your convenience, all the tags migrated from Amundsen will be in the AmundsenTags Classification. You can then keep them there or explore the Classification and Glossary capabilities that OpenMetadata brings.
Step 4 — Updating the New Services
At this point, we have the metadata snapshot we brought from Amundsen. What happens if our sources are still being updated and we want to schedule metadata syncs? Let’s head to the UI to update the sources’ connections!
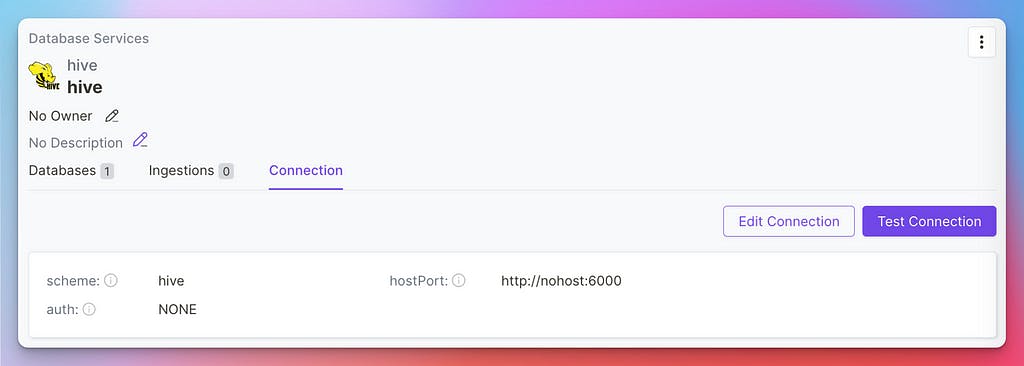
Updating the Hive connection
Click on Edit Connection to add the credentials to connect to each source and start scheduling the Metadata workflow. The good part is that for most of the Database Services, you can also create Profiler Workflows to gather further insights from your data and leverage the Data Quality features.
Summary
OpenMetadata lays a solid foundation to fuel innovation in the metadata space. As a Metadata Platform, you can leverage Discovery, Collaboration, Data Quality, and many more applications in a single place, reducing metadata fragmentation and user frustration.
In this guide, we have learned how to migrate from Amundsen, allowing us to use new and powerful tools while maintaining the context and knowledge built so far. The best part? It just takes a few minutes to set up.
If you want to learn more about OpenMetadata, visit our site! Don't hesitate to get in touch with us on Slack with questions about code, installation, and docs. For feature requests, please file a GitHub issue or contact us on Slack. Are you interested in contributing code? Here are some good starting issues to get you going.


Stuck with Amundsen? Here is how to migrate to OpenMetadata was originally published in OpenMetadata on Medium, where people are continuing the conversation by highlighting and responding to this story.