Simple, Easy, and Efficient Data Quality with OpenMetadata


Data quality and reliability are two top priorities for organizations. Many organizations have made considerable investments in Data Quality initiatives. With the current crop of tools, success has been limited due to tool disconnect, lack of collaboration, and accessibility to a broader audience.
We have a different take on how data quality should be done. Our approach has been to start with metadata. Gathering metadata based on a metadata standard allows us to contextualize data in a centralized place and to develop applications and automation on top of this metadata standard — one of which is our data quality solution.
In this blog, we’ll explore how OpenMetadata natively supports data quality that is key to many advantages — lowered cost, improved productivity, better collaboration, and many more. Let’s dive deep into some of these advantages to show why the approach taken by OpenMetadata is superior. We will use data validation tools like Great Expectations and Soda to contrast with OpenMetadata.
No need for yet another tool for data quality
With OpenMetadata, you don’t need a separate standalone system for data quality. The data quality validations are run as data workflows similar to workflows like ETL. This reduces the cost of buying yet another tool in the already fragmented data architecture and the operational costs of installing it, integrating it with various databases with various access control permissions, and managing another service.
Efficient creation and running of validation
The diagram below shows the steps for creating and running validation:

OpenMetadata reuses the existing metadata, and data source connections are already set up. For other tools, a connection to the data sources must be set up, and a duplicate copy of metadata must be created even before writing tests. Creating a test is simple in OpenMetadata; it requires only two steps and a few clicks. You can have a suite of assertions running against your table in no time. Writing validations for a table can be reduced from hours to minutes.
Rich data context makes writing validations easy
OpenMetadata provides rich data profile visualization that helps you identify data quality issues quickly and write validations to detect them, as shown below:

If you see a column with many unexpected null values, you can quickly add a test to validate for null values. If you see a column like total orders having unexpected negative values, you can add a test to check for a valid range.
No code tests to democratize data quality
For great expectations and Soda, writing tests involves installing Python packages, writing tests in YAML or Python, and running them using schedulers. This makes these tools only accessible to technical users. OpenMetadata provides simple no code and intuitive UI to allow even business users to write tests easily to democratize data quality. Suppose an analyst or a data scientist is making assumptions about the data (non-null, a range of values, cardinality, etc.); they can contribute a test to ensure those assumptions are validated. This helps build a culture where data quality is not just a responsibility of some technical users but a shared responsibility of the organization.
With the current data quality tools, there is no central place to store the tests and collect the results. You will also need to deploy and maintain a separate user interface to visualize your test results separately per project. Oftentimes, different teams write the same validations in siloes resulting in needless duplication of tests and unnecessary compute costs. All this can be avoided with the central metadata repository for all the tests and results with OpenMetadata.
Faster debugging and resolution of data quality issues
Writing validation is just the first step. These tests often fail for various reasons. Currently, debugging data quality issues requires a user to jump from tool to tool to understand lineage, schema changes, code changes, etc., as the data quality tools lack the complete context. Fixing the issue requires identifying owners and going from team to team, which can take multiple days of firefighting.
Central metadata provides one place to get the complete picture of your data instead of piecing it together by jumping across the tools. When a validation fails, all the concerned users are alerted about what is failing. The end-to-end lineage is provided to help in impact analysis to identify where the failure originated. All the changes to data and ETL pipelines are versioned, which helps identify how a change might have introduced the issue. Users can easily identify the owner of the data assets to identify who should fix the issue, start a conversation directly inside OpenMetadata, and collaborate on resolving the issue. The complete context of what failed, where it failed, how it failed, and who is responsible for fixing it helps save countless hours in debugging and resolving data quality issues.
Communication is key when there are data quality issues. With OpenMetadata, you can also quickly implement a resolution workflow. Test failures will be marked as “New” in the entity data quality dashboard, informing users of ongoing failures. The status can be changed to “Ack” for acknowledgment to let users of the table know the failure is being investigated. Once resolved, users can edit the status to resolved and choose a failure reason that best explains the incident.

Organizational Visibility to Data Quality
In OpenMetadata, you will also find a data quality health dashboard, allowing you to understand the overall health of your quality assertions. This view is available at the data asset and the organization level. The dashboard shows how the organization is doing with data quality and where improvements are needed.

Extensibility for power users
The native tests OpenMetadata offers cover a wide range of data quality dimensions. It provides assertions covering Accuracy, Completeness, Timeliness, Relevance, Uniqueness, and Validity. It enables teams from across the organization to collaborate on data quality definition to test the business standard of data sets and the engineering ones.
OpenMetadata goes one step further by making the data quality tool easily extensible. For users with SQL knowledge, our custom SQL test enables users to implement testing logic that is specific to their use case.
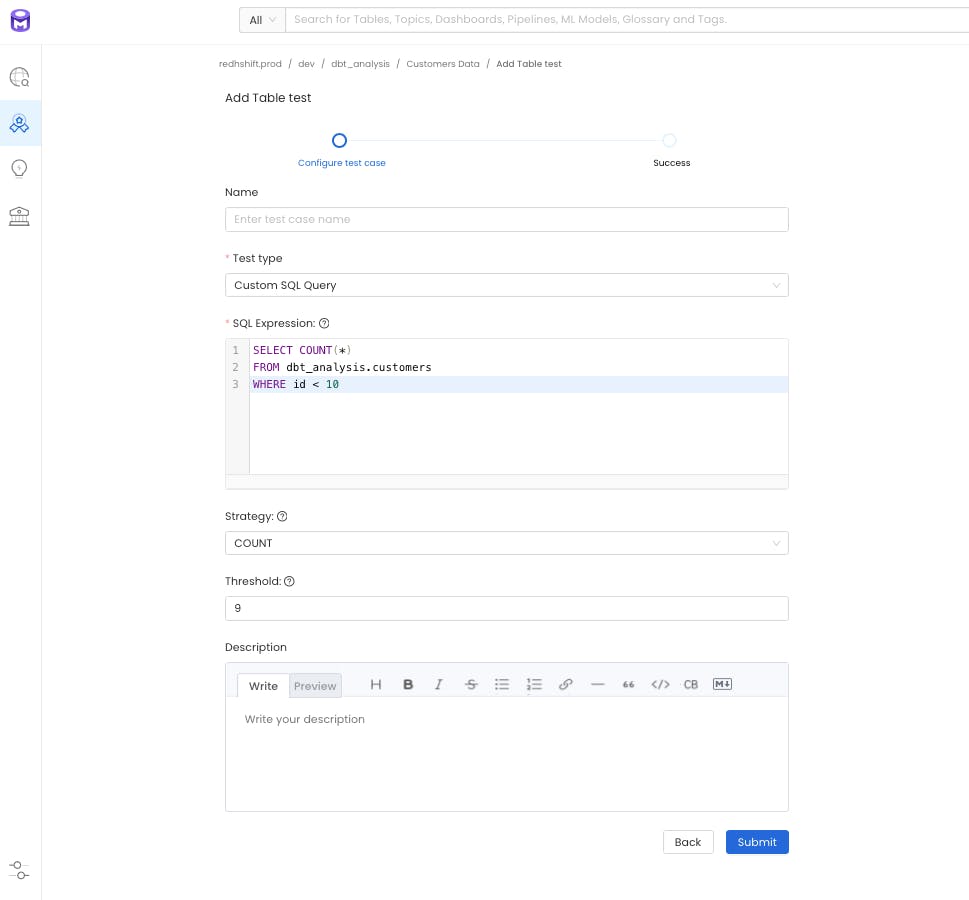
Users with Python knowledge can easily extend the OpenMetadata quality framework. You can create and define your own data quality assertions, install them inside OpenMetadata, and have your users configure them and run them directly from the OpenMetadata UI — more details here. With its extensive SDKs and APIs, it is easy to integrate OpenMetadata tests with your data processing pipeline. You can define your tests in OpenMetadata and execute them as a step of your ETL/ELT process — more details here.
While data quality programs have become strategic for organizations, few tools have approached it as such. Focused primarily on validation, requiring technical expertise, or treating metadata as a by-product, they have fallen short in solving the multiple challenges of data quality programs.
With its metadata standard first approach and easy-to-use and extensible data quality tool, OpenMetadata is the solution that can help organizations scale and foster innovation with reliable data at their fingertips.
Feature Comparison

Road Ahead
We have many amazing features related to Data Quality in our roadmap:
Anomaly Detection — Automated Anomaly detection of Freshness, Volume, Completeness, and Schema change detection.
Suggest Tests for Tables — OpenMetadata will suggest tests based on Tables and Columns using Machine Learning.
Data Diff — Show the differences between tables across different database services.
Data SLAs — Data SLAs to provide guarantees around data assets.


Simple, Easy, and Efficient Data Quality with OpenMetadata was originally published in OpenMetadata on Medium, where people are continuing the conversation by highlighting and responding to this story.