OpenMetadata Release 1.2


Domains, Data Products, Search Index, Stored Procedures, Glossary Approval Workflow, Customizable Landing Page, Applications, Knowledge Center, Cost Analysis, and lots more
Written By: OpenMetadata Team
OpenMetadata release 1.2 is packed with tons of features, making it the best Unified platform for Discovery, Observability, and Governance. We have introduced Data Mesh support with Domains and Data Products, Customization of UX for different data personas, support for new assets Stored Procedures and Search Index, the Glossary Approval Workflow, and four new connectors: Couchbase, Greenplum, Lightdash, and Elasticsearch. We have developed enterprise-specific features on Collate’s SaaS offering of OpenMetadata. To stay updated and see what’s coming next on both platforms, feel free to check out the OpenMetadata roadmap and the Collate roadmap.
Community Updates
OpenMetadata is one of the fastest-growing open-source projects in terms of features and community. We are incredibly grateful to our fantastic community for their continued interest, support, adoption, and participation.
The OpenMetadata Community Meetings have been jam-packed with attendees interested in learning more about the upcoming features. We have hosted multiple Webinars on wide-ranging topics such as Data Quality, Data Culture, Glossary and Classification, Lineage, Roles and Policies, Custom Connectors, Storage Services, and Ingestion Framework. Our recent Community Spotlight featured Haithem Souala, the Head of Data at Woop.
We proudly announce the Community Stats that are constantly on the increase:
Nearly 3000 GitHub stars (+600 stars since the last release)
Slack reached nearly 4200 members (+1000 since the last release)
192 Open-source Contributors (+24 since the last release)
Merged 931 commits into the 1.2 Release
OpenMetadata 1.2 Release Highlights
Domains and Data Products
The 1.2 release adds support for Data Mesh with Domains and Data Products. Now, you can organize your data assets, glossaries, teams, and other entities under a Domain to support decentralized data architecture. With Data Product, teams can now group the data assets offered as a product from the domains for the users. We have also introduced Domain-only View to help users stay within a domain for their data needs to simplify the user experience. Data consumers can now discover all the Data Products offered within their organization on the Explore page. Domains and Data Products offer rich documentation, versioning, and ways to capture essential metadata, such as Owner, Experts, Tags, Styling, etc.
Domains
Data Products
Search Index
Currently, many organizations are leveraging the capabilities of ElasticSearch and OpenSearch beyond their primary search functionalities, employing them as robust tools for analytics in conjunction with Kibana.
With the introduction of Release 1.2, we are excited to unveil a new data asset: SearchIndex. This addition represents a significant advancement, enabling the collection and display of metadata related to an organization’s utilization of search indexes and their associated document mappings. So, users of OpenMetadata, can now easily dig into what’s driving their analytics and search operations, document everything seamlessly, and share details about the search indexes in their setup.

Search Index Entity Details Page
Stored Procedures
Stored Procedures allow users to create business rules and transformation logic directly inside the database using SQL, Python, or Java. In this release, we have added Stored Procedures as a new entity so your team can explore and manage them as any other asset.
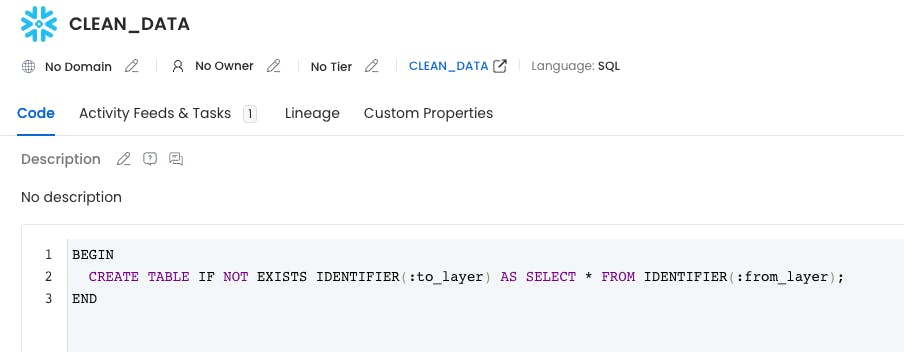
When extracting the metadata from your Database Services, we will ingest the Stored Procedures created in each schema. Moreover, we will identify which queries have been triggered by each procedure to build the lineage information with the involved tables.

In this release, this feature is supported for Snowflake, Redshift, and BigQuery, and we will keep expanding this list in the upcoming releases!
Glossary Improvements
Glossary Approval Workflow
The business glossary plays a vital role in standardizing terminology in an organization. The Glossary Approval Workflow provides control where every term added to a business glossary has been reviewed and approved by the reviewers of the glossary.
For glossaries requiring review and approval, assign reviewers, and the Approval workflow will be created automatically. When a user adds a new glossary term, it starts in the Draft state, and an Approval Task is created for the reviewers. Only the assigned reviewers can approve or reject the glossary term. As a collaborative platform, it is easy to start conversations in OpenMetadata to discuss the terms added to the Approval queue by pulling in more team members into the conversation by @ mentioning them. When a reviewer approves the term, the state is changed to Approved, and it becomes available for use in the organization. A reviewer can reject the term, changing its state to Rejected. If a Glossary does not have a Reviewer set up, the newly added Glossary Terms are approved by default.
Glossary Approval
Glossary Styling
With glossary styling, you can introduce a range of colors and icons to stylize your business glossary. Get a one-glance view of the related concepts and terms by color-coding the terms and by adding icons. You can add glossary terms to tag the Data Assets. The color-coded glossary terms make it easier to differentiate and identify the data assets visually.
Custom Attributes
OpenMetadata supported the addition of custom attributes to various data assets. Now, you can add custom attributes to both Glossary and Glossary Terms. Go ahead and enrich your business glossary with more information relevant to your organization.
Customizable Landing Page
Customize Landing Page
OpenMetadata is revolutionizing the Metadata Platforms with an amazing UI that caters to Technical and Business users alike. In Release 1.1, we overhauled the entire UI and built a brand-new user experience. We have received overwhelmingly positive feedback, with Users and Organizations telling us that this is by far the best product they have used.
So far, the UX has been the same for all the users, irrespective of their job function. In release 1.2, we are introducing the concept of Personas to tailor the UX to the needs of different types of users. You can customize the Landing Page for Data Engineers, Data Scientists, Analysts, Data Stewards, and Data Citizens. If a user plays multiple roles, they can choose any one of the personas assigned to them.
OpenMetadata supports a new entity called Knowledge Panels as the building block for customization. We have a growing list of knowledge panels for Activity Feed, My Data, Following, Announcements, KPIs, Quick Links, etc. A Data Scientist can have My Data, Following, and Announcements. A Data Engineer can have additional technical panels, such as Pipeline Status, to see the success or failures of pipelines they own, and Test Status to check data quality issues. For non-technical users, you can create a much simpler experience with fewer Knowledge Panels and include Quick Links on how to get started. You can position these knowledge panels to customize the information hierarchy on the landing page.
In the future, we will add more Knowledge Panels and support customization of other pages so that Table, Topic, Dashboard, and Glossary pages can be further tailored for Personas.
Build Automation Applications
Metadata Applications
OpenMetadata set out to bring all the metadata under one platform powered by metadata standards and APIs with a vision to empower organizations to build powerful automation.
With Release 1.2, OpenMetadata is shipping the latest innovation in the data world, Metadata Applications. We have developed a comprehensive Framework and API suite that opens the door for third-party applications, as well as our own solutions. Admins can browse available applications in a marketplace and install their choices with ease. During installation, each application will request metadata access permissions detailing its functionality.
In Release 1.2, we are shipping three key applications that OpenMetadata users are familiar with:
Data Insights: harnesses collected metadata to generate analytics, providing insights into the growth rate of data assets, description and ownership coverage, OpenMetadata usage patterns, and identifying the most viewed data assets.
Data Insights Reports: empowers organizations to set KPIs, such as Ownership and Description Coverage, as universal goals. Data Insights Reports facilitate this process, sending weekly email reminders to all teams, helping them track their progress against organizational KPIs.
Search Indexing: While OpenMetadata offers live metadata indexing into Elastic or OpenSearch services, there can be lapses in indexing updates due to search service downtime. The Search Indexing application ensures consistency, allowing for periodic updates to be published and ensuring that the search always reflects the latest changes in OpenMetadata.
The Metadata Applications is a revolutionary innovation enabling automation powered by metadata.
Knowledge Center — Collate only
Knowledge Center
As organizations increasingly rely on OpenMetadata for discovery, collaboration, data quality, observability, and governance, there is a noticeable gap in housing long-form articles that describe architecture, showcase usage tutorials, and document best practices in data management. Traditionally, teams might turn to tools like Google Docs or Confluence to document these extensive details. However, with more users making OpenMetadata their go-to hub for all things data-related, there’s a clear need for a connected experience and eliminate jumping between OpenMetadata, Google Docs, and Confluence wiki pages in search of pertinent articles.
Release 1.2 introduces the “Knowledge Center” — a brand new feature designed to enhance your data documentation and centralize tribal knowledge.
The Knowledge Center supports the creation of in-depth, long-form knowledge articles using our innovative new editor. This tool not only facilitates rich content creation, embedding images, and other media to elucidate complex details, but also enables users to tag teams and data assets as references, fostering a seamless connection between documentation and data assets. Knowledge Articles come equipped with comments, version history, and all the other great features that OpenMetadata users have come to appreciate for other data assets.
In conjunction with our Customizable Landing Page feature, Release 1.2 also adds the Knowledge Center panel, which can be seamlessly integrated into users’ landing pages. Now, critical knowledge and documentation are readily available where users need them, making OpenMetadata a comprehensive hub for all things data.
Cost Analysis Report — Collate only
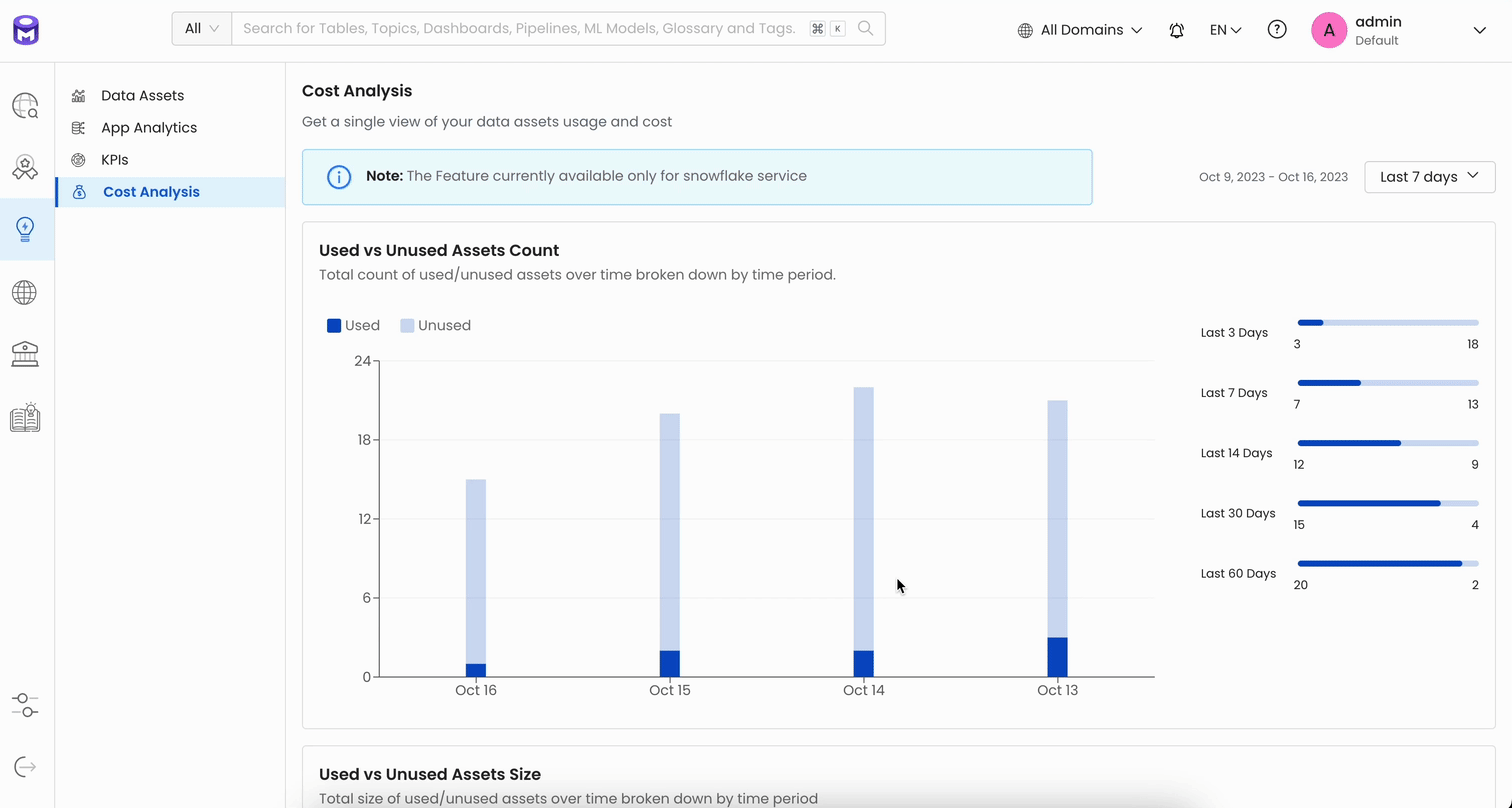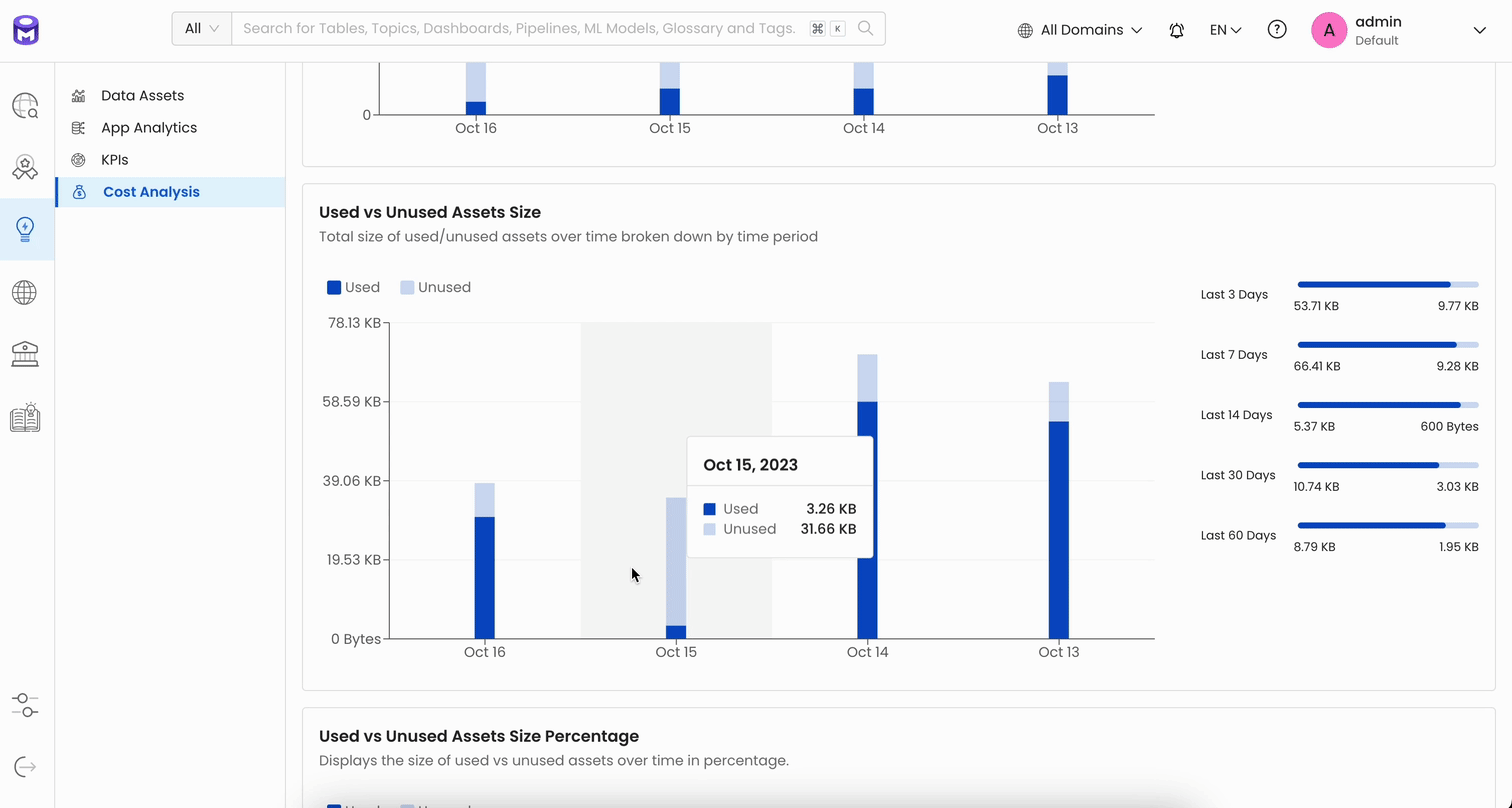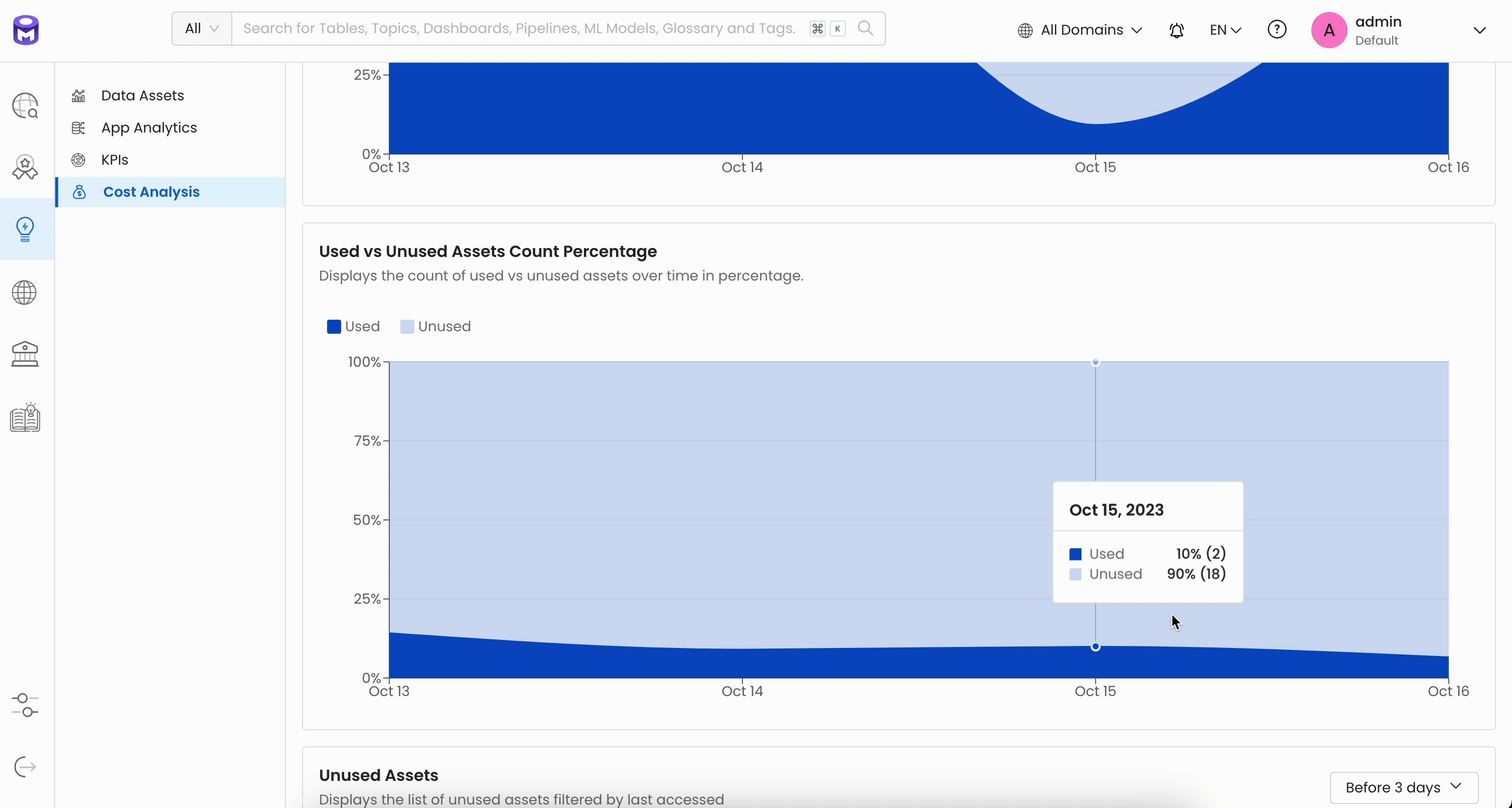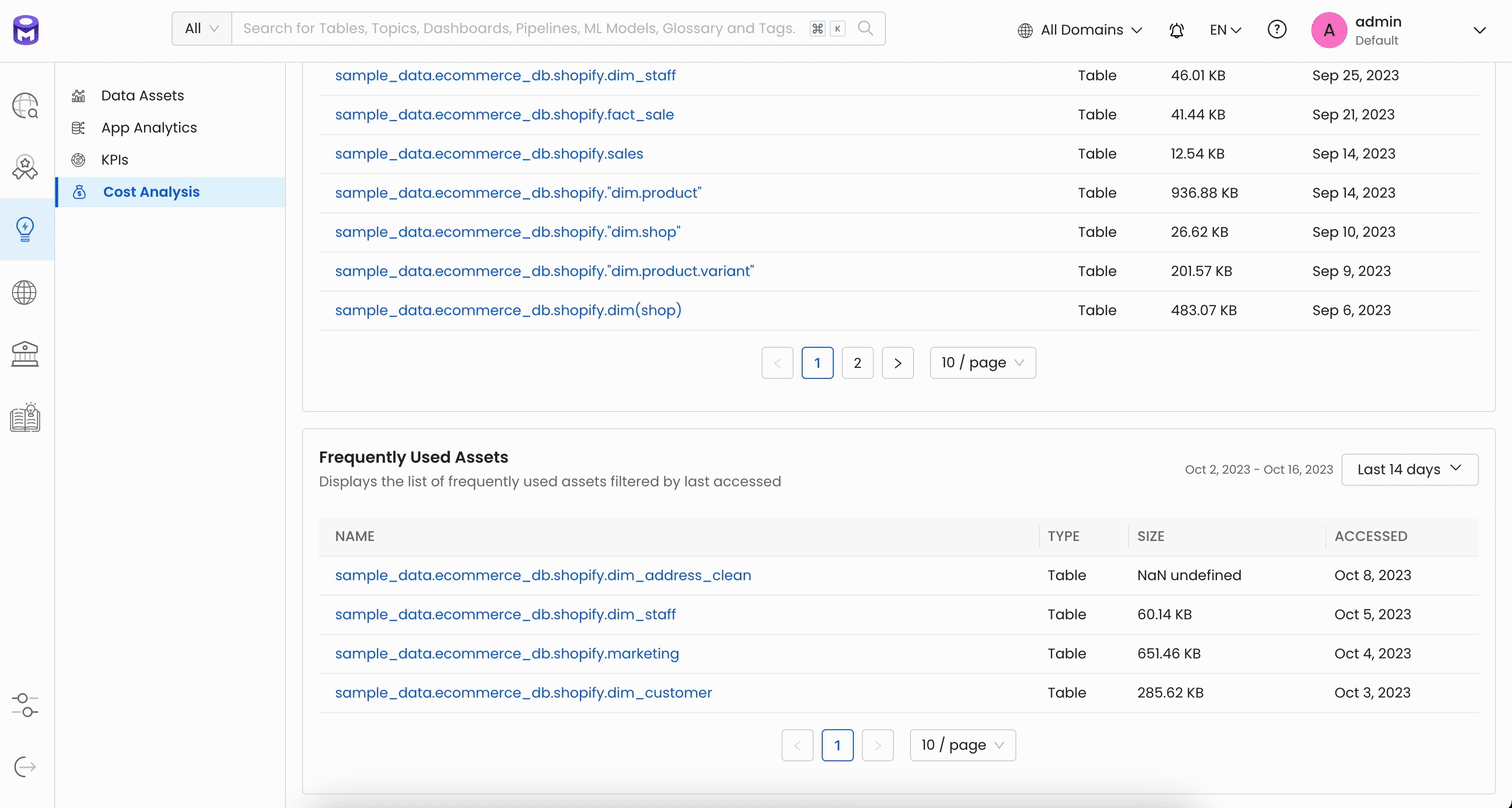
Cost Analysis
Data leaders today are investing a lot of money into data infrastructure and data teams to make smarter decisions and ultimately grow their businesses. However, one challenge that keeps coming up is figuring out the actual return on investment (ROI) of these data initiatives. Questions like “Is the data we’re storing actually being used?” or “Is anyone really looking at the dashboard we spent a whole month creating?” are common and quite tricky to answer. Getting to the bottom of these questions is really important to know if a company’s efforts in data are paying off or not and to eliminate unnecessary costs.
With Release 1.2, we’re introducing the Cost Analysis Report as a solution to this problem to help organizations understand their data usage better. It will point out which data assets are getting a lot of use and which ones are not, and it will show how much data is being stored and how many terabytes of it are just taking up space without providing any real value.
We plan to expand the capabilities of the Cost Analysis Report even further by showing unused data across different data warehouses, calculating the cost of query run times, and identifying unused dashboards and unneeded data pipelines. All of this is aimed at giving data leaders the information they need, not just to cut unnecessary costs but also to make sure their data infrastructure is lean, efficient, and focused on the right data for better decision-making.
OpenMetadata Browser Extension
OpenMetadata stands out with its array of features designed to facilitate data collaboration, including activity feeds and task management, all aimed at unlocking the wealth of tribal knowledge embedded with the data. We believe that all the documentation, tags, and metadata added by users in OpenMetadata should be easily accessible, right at their fingertips.
Consider a user working on a dashboard; envision a scenario where they can effortlessly retrieve information about the dashboard’s ownership, its documentation, associated tags, and the tables it utilizes using lineage, all without stepping away from their current task. This seamless integration is crucial for efficiency and knowledge sharing.
To bring this vision to life, OpenMetadata takes pride in being the pioneering project to ship the browser extension that transports metadata directly in user’s active workspaces, using the context of what users are working on.
In Release 1.2, we have significantly upgraded the browser extension to enhance user experience:
Revamped UI: now includes the user’s activity feed and task management to help users stay updated with organizational changes in data.
Comprehensive Metadata Support: Supports a wide array of assets, including Snowflake, Postgres, Airflow, Superset, Looker, and many more.
Metadata Editing Capabilities: Users can now edit and update metadata directly from the browser extension, be it adding a new tag or updating a description.
By bridging the gap between users and metadata, OpenMetadata enhances data understanding, collaboration, and efficiency across the board.
Lineage
Lineage has been — and will continue to be — a major focus area in OpenMetadata. Being able to infer both table and column-level lineage from queries automatically is paramount. Data Platforms continue to grow in number of assets and complexity, so automatically identifying the flow of data is one of the most used features by our users.
We have continued to expand our parsing capabilities with more contributions to SQLFluff, one of the foundations of our lineage module. We have improved the query parsing speed by cutting the parsing time in half.
Connectors
In the 1.2 Release, OpenMetadata introduced four new connectors — Couchbase, Greenplum, Lightdash, and Elasticsearch. The Azure Data Lake Storage (collate icon) connector is supported for Collate only.
The Services page now supports the new List view and the Card view for onboarded services. Here are a few other changes related to integrations:
When deploying an ingestion workflow, users can now configure the number of retries if a workflow fails.
In the Profiler ingestion, you can choose to ‘Include Views.’
We now bring column-level lineage for Spark jobs from Spline.
When ingesting metadata from Dashboard services, you can filter (include/exclude) by Projects.
SSL support has been added for Apache Superset.
The Datalake nested columns sample data ingestion has been updated.
Localization
We now support localization for German. The existing localization support for Chinese has been updated. In the previous releases, we supported the following languages: English, French, Chinese, Japanese, Portuguese, and Spanish.
Other Changes
Several other changes have been made.
Support added for 👍 upvoting data assets.
Search by FQN.
Search support on the Schema page.
Advanced search modal now supports custom property filters.
In the Schema tab, now we can also filter by Tags and Glossary.
Filtering by Tags and Glossary is supported for Table, Topic, Pipeline, Dashboard, and Container.
The Display Name for Tiers can be edited to rename the Tiers as per the vocabulary in use in your organization.
Announcements are now supported for all the services like Database, Messaging, Dashboard, Pipeline, ML Model, Search, and Storage. You can also add announcements for Database, Database Schema, Dashboard Data Model, Stored Procedure, and Container.
The Teams page now supports Subscription webhooks. So Admins can connect their teams to Slack, MS Teams, or Google Chat.

Thanks to our Contributors
We are grateful to the following users for their code contributions:
Anatoliy Shulika, for the Greenplum connector.
Artiom Darie, for adding support to connect to AWS RDS and PostgreSQL using IAM roles authentication.
Cristian Calugaru, for adding support for a global manifest file containing all paths across all buckets that need to be ingested by a storage service.
Gautham Kishore, for adding support for the Lightdash connector.
Joseph Goldbeck, for updating the documentation.
Keagan O’Donoghue, for working on the MSSQL connector docs.
Louie, for updating the localization support for Chinese.
Mitchell Mann, for adding support for the Presto table and column comments during data ingestion.
Nguyen Huu Loc, for adding support for Looker multi repos, the lineage from the tables to LookMLView, and for updating Looker.
Preet Shah, for working on the Maven build with SonarCloud.
Ryo Ariyama, for changes in PowerBI.
Supan Shah, for changes to AWS Sagemaker.
Vanshika Kabra, for supporting column lineage from Spline and upgrading MLFlow.
Vlad, for editing the documentation.
VolkovGeoPhy, for updating Great Expectations.
William Geuns, for changes related to Great Expectations.
A special thank you to the first-time contributors — Anatoliy Shulika, Artiom Darie, Joseph Goldbeck, Keagan O’Donoghue, Mitchell Mann, Nguyen Huu Loc, Preet Shah, Ryo Ariyama, Sarath Saleem, Vlad, and William Geuns.
Thanks to the following users for providing feedback on GitHub that made it to the 1.2 release — Abrahan Torres, Aitana Jiménez Facephi, Alina Valea, Alekseev Vadim, Allen Haozi, Andrew Logvinov, Anna Shevchuk, Badr A., Bukreevai, Carsten Agger, Chris Utz, Cristian Calugaru, Cristiano Dicrescenzo, CV Lendistry, Deepak Tripathi, Denis Kirichenko, Dominik Kalisch, DovileKr, DykVanDyke, Felipe Arruda, Flavio Altinier Maximiano da Silva, Gabriel Nogueira, Gavin Dew, geoHeil, Giacomo Chiarella, Gnomolio, Hansh, Hendrix, Hoang Do, Isabela Angelo, Isoctcolo, Itai Sevitt, Ivpnoida-tj, Jacek Śpiewak, Jason Clark, Javier Cózar del Olmo, Jeremy Tee, Jesse van Elteren, Jetpacula, Joal Wood, Joe Jordan, Jon Erik Kemi Warghed, Jonathan Bonnaud, Joseph Goldbeck, Josh Liberty, Jromandv, Jürgen Zornig, Kirill Bartosh, KA Kuznetsov, L Pontes, Laila Patel, Leonid, Magpest, Maniar Sagar, Marcos Online App, Martin Majtan, Martin Trillhaas, Miki Horn, Mrkoloev, Naeshaun Medal, Nguyen Huu Loc, Nitisha Desai, Noe Alejandro Perez Dominguez, Noel Gomez, Oleg Savko, Oscar Kuo, Pauline Tolstova, Petemce, Pranjal Chandel, Pyangzen, Ph-eip, Raghav Khatoria, Rahul Sharma, Rinaldo Catroque, Ruth-Mills-Naimuri, Saad Amien, Sapir Hirshberg, Seçkin Dinç, Sidharth Pallerla, Siimon Härm, Stéphane Sol, Supan Shah, Taqi, Tyler Pegram, Upen Bendre, Yifeng Jiang, Yogic Wahyu Rhamadianto, and Yu Ishikawa.
Please get in touch with us on Slack if you have questions about code, installation, and docs. For feature requests, please file a GitHub issue or contact us on Slack for feature requests.
Are you interested in contributing code? Here are some good starting issues to get you going.
And don’t forget to support us with a GitHub star if you like what we are doing! That will help OpenMetadata reach a wider audience and build a community to solve data problems together.

OpenMetadata Release 1.2 was originally published in OpenMetadata on Medium, where people are continuing the conversation by highlighting and responding to this story.