Incremental Extraction Improves Metadata Ingestion in Collate


Most traditional data catalogs and metadata systems perform only full extractions: querying metadata for every object in the source system — tables, views, columns, ownership, tags, descriptions — on every scheduled run. While this ensures completeness, it becomes inefficient at scale, especially in data warehouses with thousands of objects where only a small fraction change daily. And this metadata ingestion only grows more expensive with every new table, database, and data source added to your stack.
Collate's Incremental Extraction capability upends this paradigm. Instead of scanning everything every time, it intelligently identifies and processes only the metadata that has actually changed since the last run. The result? Up to 89% faster data ingestion, dramatically lower cloud costs, and metadata pipelines that scale efficiently with your data's rate of change — not its total size.
This enhancement in our managed OpenMetadata service is now available for Snowflake, BigQuery, and Redshift, with support for additional sources coming soon.
Incremental Extraction Boosts Speed and Efficiency
Running full metadata extraction on every ingestion cycle may seem to be a harmless default — until you're managing hundreds of workflows across thousands of tables. At enterprise scale, it can create significant problems:
1. Compute Time Wasted on Redundant Work
Every full ingestion cycle processes metadata for all tables — even those that haven't changed in weeks or months. This results in long-running workflows that can waste up to 95% of compute cycles without delivering new or useful information to your metadata catalog.
Consider a typical enterprise scenario: 10,000 tables with daily ingestion, where only 5% change daily. Traditional approaches to data ingestion can waste 95% of their compute cycles on unnecessary work. When you’re working across multiple environments and data sources, you can burn hours of compute time on operations that don’t provide value.
With Incremental Extraction, workflows focus exclusively on changed metadata, delivering significantly faster runs, lower costs, and fresher data to downstream consumers.
2. Unnecessary Cloud Spend
For teams using cloud data warehouses like Snowflake, RedShift, and BigQuery, every query has a cost. Relying on full extractions creates:
Higher data-warehouse compute spend for system metadata queries
Increased API usage costs, particularly when audit logs are involved
Compounding expense as your data footprint grows
The last point is particularly relevant as data volumes expand for AI readiness because the impact of extraction inefficiency grows along with the size of your data footprint.
3. Scale with Change, Not Size
With a traditional full-extraction approach, every new table permanently increases your ingestion overhead. This linear relationship between environment size and ingestion cost makes growth expensive.
Incremental Extraction breaks this pattern by scaling with change volume, not environment size. Whether you have 1,000 tables or 50,000 tables, if only 100 changed today, you pay to process only those 100.
How Incremental Extraction Works
At its core, Collate’s Incremental Extraction feature is an intelligent alternative that transforms metadata ingestion from a "scan everything" approach to a "smart detection" system. It reduces unnecessary processing during metadata ingestion by identifying and updating only the tables that have experienced metadata changes since the last ingestion run.
Quantifying the Performance Improvements
To evaluate the real-world impact of Incremental Extraction, we tested ingestion workflows across Snowflake, BigQuery, and Redshift, simulating different levels of metadata change. The goal was simple: measure how ingestion time scales when only a fraction of the metadata has been modified. The results demonstrate substantial efficiency gains.
For each source, we measured ingestion time under a baseline full ingestion (non-incremental mode) and multiple incremental runs, each simulating a different percentage of tables with metadata changes (100%, 90%, 50%, 25%, 10%). This let us isolate the efficiency gains of incremental mode across varying data change volumes.
Performance Benchmarks (10% Change Rate)

Not surprisingly, the biggest benefits came in scenarios with smaller change rates. At a 10% change rate, the average time savings was 58% across all platforms. But at a 25% change rate, Incremental Extraction still achieved 40% - 50% time reduction. And with a 50% change rate, Incremental Extraction maintained 25% - 35% efficiency gains.
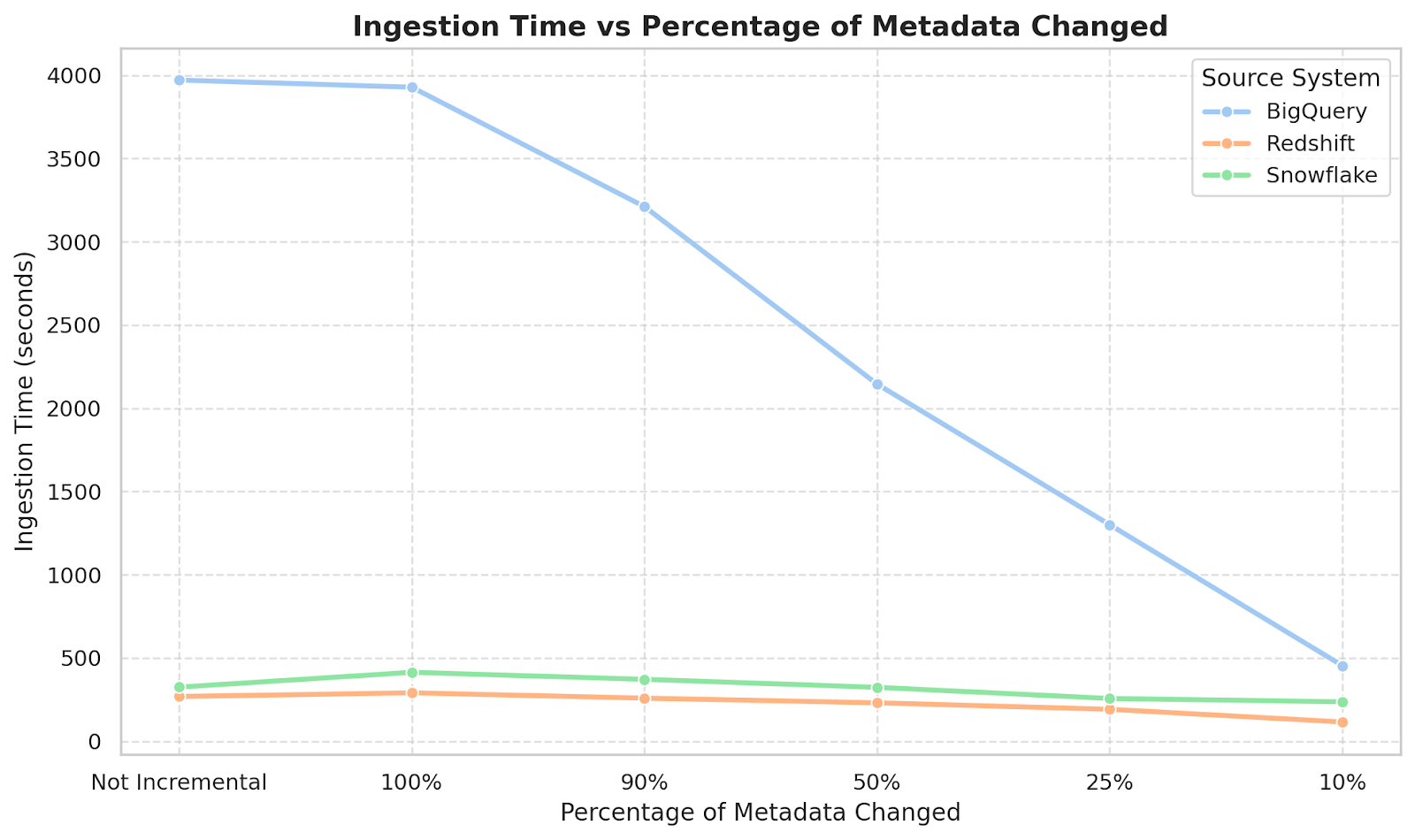
All these improvements bring proportional reductions in cloud compute and API costs that compound over time. For organizations running multiple daily ingestion jobs, the cumulative savings can be substantial.
Incremental Extraction = Smarter Metadata Management
Incremental Extraction represents a fundamental shift in how metadata ingestion operates — from brute-force scanning to intelligent change detection. For organizations managing large-scale data operations, Incremental Extraction offers immediate benefits: reduced costs, faster ingestion, and metadata pipelines that scale intelligently with your data's rate of change, not its total size. But this capability isn't just about faster ingestion times; it's critical to building sustainable, cost-effective metadata management practices that scale efficiently as your organization grows. By reducing unnecessary processing time by up to 89%, Incremental Extraction makes metadata management more affordable and more efficient.
Just as important, the new feature demonstrates Collate's commitment to solving real operational challenges faced by data teams at scale. As data environments continue to grow in complexity and scale, capabilities like Incremental Extraction become increasingly essential for maintaining operational efficiency.
Next Steps
Ready to optimize your metadata ingestion? Try Incremental Extraction in your Snowflake, BigQuery, or Redshift environment and experience the difference intelligent metadata management can make. Here are some good ways to get started:
Read our docs: Learn more about using Incremental Extraction
Try Collate Free Tier: Experience our free managed OpenMetadata service
Schedule a demo: See how Collate works with your data stack
Join our community: Connect with other data teams transforming their data practices