Data Governance that runs itself with Collate Metadata Automations


As data and teams scale, managing metadata manually becomes increasingly complex. What starts as simple tasks—assigning ownership, writing descriptions, or associating glossaries—becomes difficult and time consuming as your data platform and organization expands.
To address this, we've introduced Collate Metadata Automations on our managed OpenMetadata service: a no-code solution for governance at scale through rule-based automation. This comprehensive capability automates metadata assignment of ownership, descriptions, glossaries, domains, tags, tiering, PII, and more. Lineage propagation of this metadata is also available to save time and ensure consistency. And when combined with Collate AI’s automated description generation, these tasks can now be done even more efficiently. Data governance, business, and data platform teams can now deliver accurate and consistent metadata coverage across the data estate, which ensures better governed and more discoverable data, with significant time savings.
The challenges of metadata management at scale
Managing your metadata is essential for clean, reliable data that can be used by your organization. Tables and columns without description metadata are hard for data users to find or understand: how do you know which data to use when faced with names like orders, fact_orders or prod_orders? Data assets without ownership make it difficult to find who can fix data problems or answer any questions. Missing PII tags can lead to personally identifiable information slipping into reports, dashboards, and ML models, risking both government fines and company trust. Simply put: without proper metadata, effective data management becomes impossible, especially at scale.
As data grows in scale and complexity, metadata management requires new approaches. While small teams with limited data volumes can manage metadata manually—documenting descriptions and ownership in a few hours, maintaining routine hygiene tasks—these manual processes break down as organizations grow. When multiple teams manage numerous data sources with frequently evolving datasets across different environments, they need more advanced approaches. Otherwise, data platform teams will face various problems:
Time consuming, manual, and error prone metadata generation and updates
Confusion due to inconsistent, incorrect, or missing owners, descriptions, and PII tagging between upstream and downstream data
Inability to prioritize and organize higher importance data by tiering, business domains, or glossaries
Poor metadata management impacts downstream data practitioners and business users in different ways:
Difficulty finding the right data and understanding how to use it due to missing descriptions and glossaries
Data Quality issues leading to incorrect reports, poor decision making, and eroded trust
Regulatory penalties and compliance risk from gaps in PII governance
After seeing these challenges with our customers and community, we set out to develop a better approach to managing metadata, particularly for teams and data at scale. It needed to automate manual processes, be robust enough for large enterprises with hundreds of thousands data assets and tens of thousands of data practitioners, while remaining accessible for non-technical data users.
Collate Metadata Automations to automate metadata management
Collate Metadata Automations is a no-code solution to help governance, business, and data engineering users answer key questions like:
What are our most critical data assets?
Who is responsible for this source?
Are we properly tagging PII data?
Through an intuitive graphical interface, users can create rule-based automations to select and filter down data assets, and to create rules for managing metadata in bulk. This includes ownership, descriptions, glossaries, domains, tags, tiering, PII, and more. These rules can be run on your current data as a one-off job for initial metadata population, or scheduled to be run on an ongoing basis to ensure your metadata remains complete and consistent even as new data arrives into your platform.
A walkthrough of how to use Metadata Automations
Before jumping into the process of creating an metadata automation, let’s look at some common scenarios that data teams encounter:
All tables from the GOLD database are Tier 1.
When the account_number column is used, associate the Account Number Glossary Term.
Maintain consistent descriptions and tags through lineage.
These scenarios follow a common workflow:
First, select which data asset types we are applying the automation to. Are we working with tables? Dashboards? All assets?
Then, filter these assets to the ones we want to change metadata, using a set of conditions. There are 14+ conditions available to narrow down the right set of assets, including domain, service, tier, and even custom properties. Preview your selection through the filtered Explore page link to ensure you've targeted the right assets.
Finally, specify the actions we want to perform on this filtered subset of assets: add tags, descriptions, lineage propagation, etc. Each action can be configured independently, including whether to overwrite existing metadata.
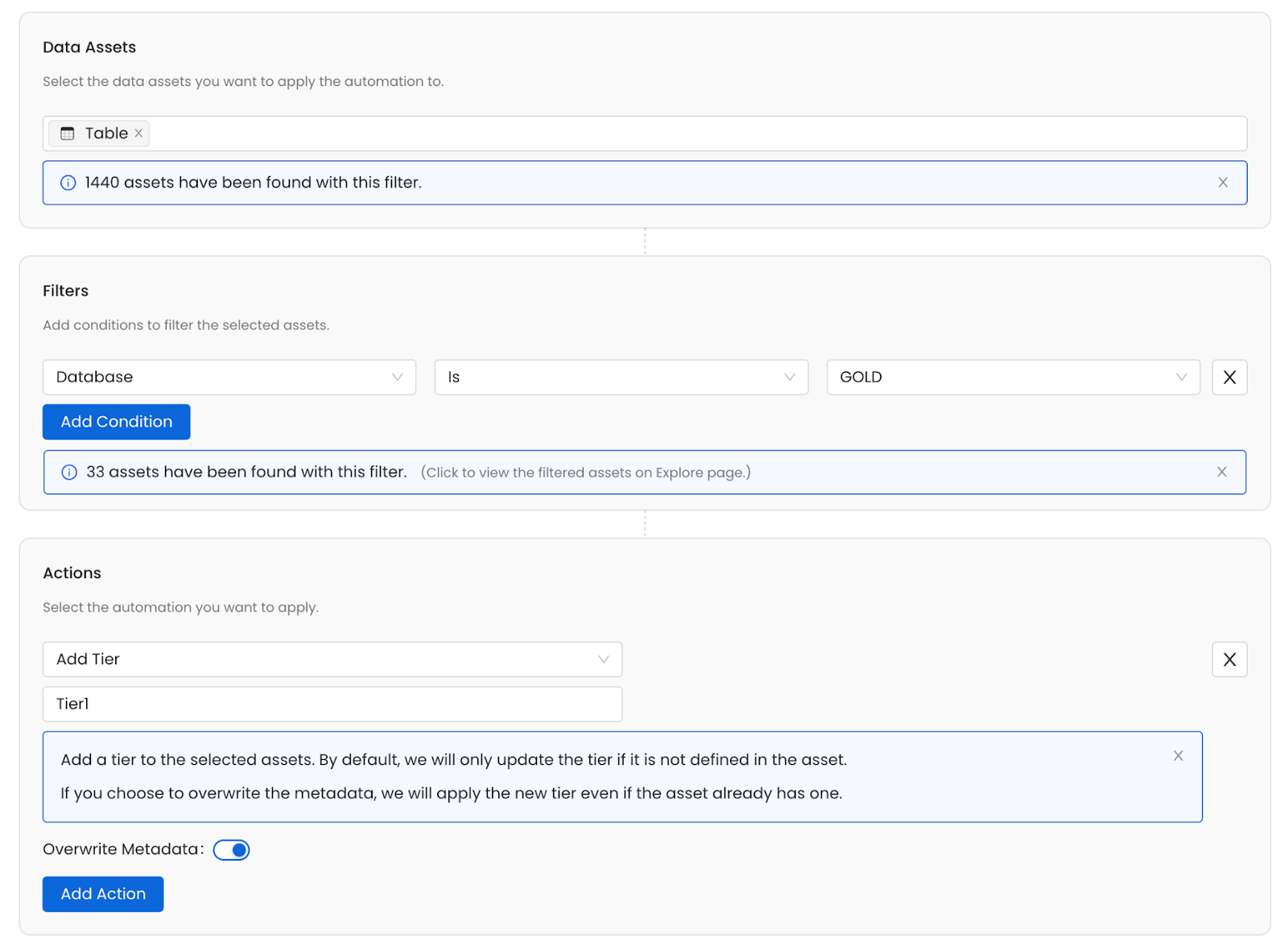
We can then save the automation as a one-time job, or schedule for recurring execution.

And that’s it. We’ve designed Metadata Automations to be simple for non-technical data practitioners to easily manage metadata at scale across your data estate.
Common use cases for metadata management
We can apply Metadata Automations to a variety of use cases to improve data governance and discovery for your organization.
Prioritize efforts with tiers
Data needs can vary significantly across teams and projects. A missing description in a test sandbox may have little impact, but incomplete metadata for data sources powering company KPIs can severely affect business decision making.
Tiering is a powerful classification system that helps you identify your most critical and frequently used data assets. By implementing tiers, teams can focus their efforts where they matter most—maintaining high standards for data hygiene, infrastructure uptime, and support SLAs. Metadata Automations ensures that the right tier is given to each table within services or databases, and future scheduled runs can handle any new tables without any additional effort.
Associate glossary terms in bulk
A centralized knowledge base for your business terms helps your team find the correct data, and more importantly, follow the same conventions and definitions. Business trust erodes when different groups answer the same question ("How many orders have we shipped?") differently because they define terms inconsistently ("What counts as an order?").
Maintaining up-to-date links between your data assets and their associated glossary terms provides essential context for correct data interpretation. With automated metadata workflows bridging your technical and business worlds, you can improve data discovery and collaboration between technical and business data users.
Keep ownership up to date
Data that isn’t owned can be worse than no data at all. Who handles data quality issues? Who ensures data arrives at the right time and place? Who enforces governance and security policies? Using unowned data risks poor reporting and flawed decisions downstream. Ownership is a central piece of any successful governance strategy, and with Metadata Automations, you can make it simple for owners to maintain accountability for their data assets.
Assign the right domains
Domains and data products aim to help decentralized teams manage and share their data. Now, you can use Metadata Automations to assign and keep your assets to the domain to which they belong.
At Collate, we enabled RBAC principles based on Domains to help different personas focus on the data they need. When working on companies with decentralized domains, you want to ensure which assets are internal and must remain private vs. which Data Products you are publishing inside the organization. Metadata Automations can ensure that your data remains in your domain regardless of how it evolves.
Automated PII Tagging
You can follow different strategies to protect sensitive data:
Use Metadata Automations to bulk apply PII tags, or leverage our NLP models to identify PII from column names and sample data.
Crowdsource PII knowledge using the platform's collaboration capabilities, including discussions and tag suggestions.
Linking assets to glossary terms to automatically propagate PII tags to related data
Propagate descriptions, tags, and glossaries through lineage
Properly describing and tagging data requires deep understanding of data sources and is often a collaborative effort. Maintaining consistency while avoiding duplicate effort is necessary for managing this work at scale. Collate offers industry-leading column-level lineage capabilities, including for metadata management. Our lineage propagation workflow automatically annotates descriptions, tags, and glossary terms through column-level lineage to ensure this metadata is consistent and reliable.

Check out the product deep dive video of Metadata Automations
To see Collate Metadata Automations in action, check out this product deep dive video to see this feature being setup and run, including with lineage propagation.
Conclusion and next steps
Collate Metadata Automations is a significant step forward in solving the challenges of metadata management at scale. By offering a no-code solution for automating ownership, descriptions, PII tagging, and other critical metadata tasks, organizations can now maintain consistent governance across their entire data estate without the burden of manual processes. When combined with capabilities like Collate AI’s automated description generation and lineage propagation, teams can dramatically reduce the time and effort required for metadata management while improving accuracy and coverage. This comprehensive approach ensures that as your data platform grows, your metadata management can scale efficiently, enabling better data discovery, governance, and trust across the organization.
Metadata Automations is a Collate commercial feature for our managed OpenMetadata service . You can try it out today in the live product sandbox with demo data, or by signing up for Collate free tier to use with your own data assets.