Data Diff in OpenMetadata and Collate


In large-scale data operations, data is continuously transformed, migrated, and replicated across different systems. Ensuring the consistency of this data—especially between systems like OLTP databases and OLAP warehouses—is a challenging but crucial task. This is where data diff becomes vital. The ability to compare tables across environments, databases, or different points in time is essential for identifying discrepancies that could lead to faulty analysis or decision-making downstream.
Data diff adds a critical layer of validation, allowing data engineers to proactively catch errors in ETL jobs, replication processes, and migrations. Whether it’s validating that no data was lost during a migration or ensuring that transactional data in production is accurately reflected in analytics, data diff provides the granular insight needed to maintain high data quality. It is the latest feature in OpenMetadata’s data quality framework, and available in Collate’s managed OpenMetadata service, that supports defining no-code or low-code testing data quality specifications to give data platform, data science, and infrastructure teams better confidence in their data as it moves through different environments.
Data Consistency Problems: The Story of a Retail E-commerce Platform
In this post, we will explore the significance of the data diff feature by diving into three scenarios at a large retail e-commerce company, where multiple teams—data engineering, data science, and infrastructure—must collaborate to ensure seamless data quality throughout the entire data pipeline.
Let’s imagine a data platform with a large database where data is processed, transformed, and used by different teams. The teams are responsible for maintaining data consistency and ensuring that data is neither dropped nor altered incorrectly during ingestion, transformation, or migration.
Data Engineering Team: ETL Validation
The Data Engineering team manages the pipelines that ingest transactional data from a raw table (raw_orders) from the data lake into the final fact table (fact_orders). The raw_orders table contains hierarchical data of customer transactions, with details like product IDs, prices, quantities, and timestamps. In fact_orders, the data is flattened, curated, and made available for analytics for the rest of the organization.
Before they can deploy a new ETL pipeline that handles the transformation from raw_orders to fact_orders, they need to validate that all records from raw_orders were correctly loaded into fact_orders, ensuring no rows are dropped, duplicated, or altered.

Data Diff Test Example
The team can use OpenMetadata’s data diff feature to ensure that all data from raw_orders was accurately transferred to fact_orders, without loss or duplication. Any discrepancies will be highlighted for quick resolution, ensuring data integrity before new pipelines that use fact_orders go live.
Data Science Team: Feature Engineering Consistency
The Data Science team uses tables like dim_customers (which contains customer demographics such as previous purchases, region, and segments) and fact_orders to develop predictive models for customer behavior. As they iterate on their models, they want to ensure that only new features (e.g., customer segmentation logic) are added or updated. At the same time, core attributes like age and region remain consistent.
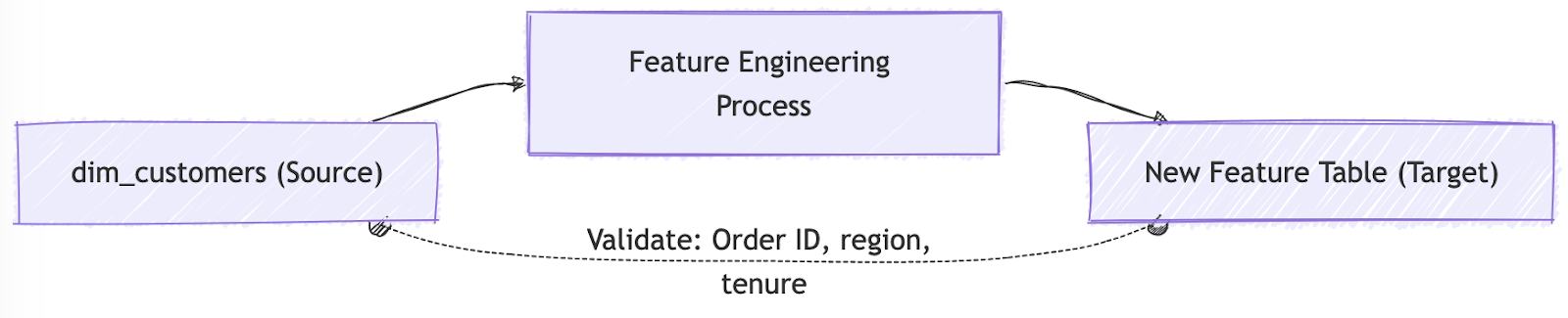
Data Diff Test Example
The team can run a data diff test to ensure that age and region remain unchanged during feature engineering iterations, ensuring that only the intended attributes have changed.
Infrastructure Team: Database Migration
The Infrastructure team is responsible for continuously syncing data between the e-commerce platform’s transactional system and a cloud-based data warehouse. Instead of performing a one-time migration, they are managing ongoing data replication processes to ensure that data is consistently available for analytics and reporting in near real-time. This includes syncing critical tables such as fact_orders, which contains all transaction data, and dim_customers, which contains key customer demographics.
Given the volume of transactions and the complexity of the systems involved, the team needs to constantly validate that data replication is functioning as expected. They must ensure that no records are lost, altered, or duplicated during the replication process and that the data in the cloud warehouse remains in sync with the transactional system.
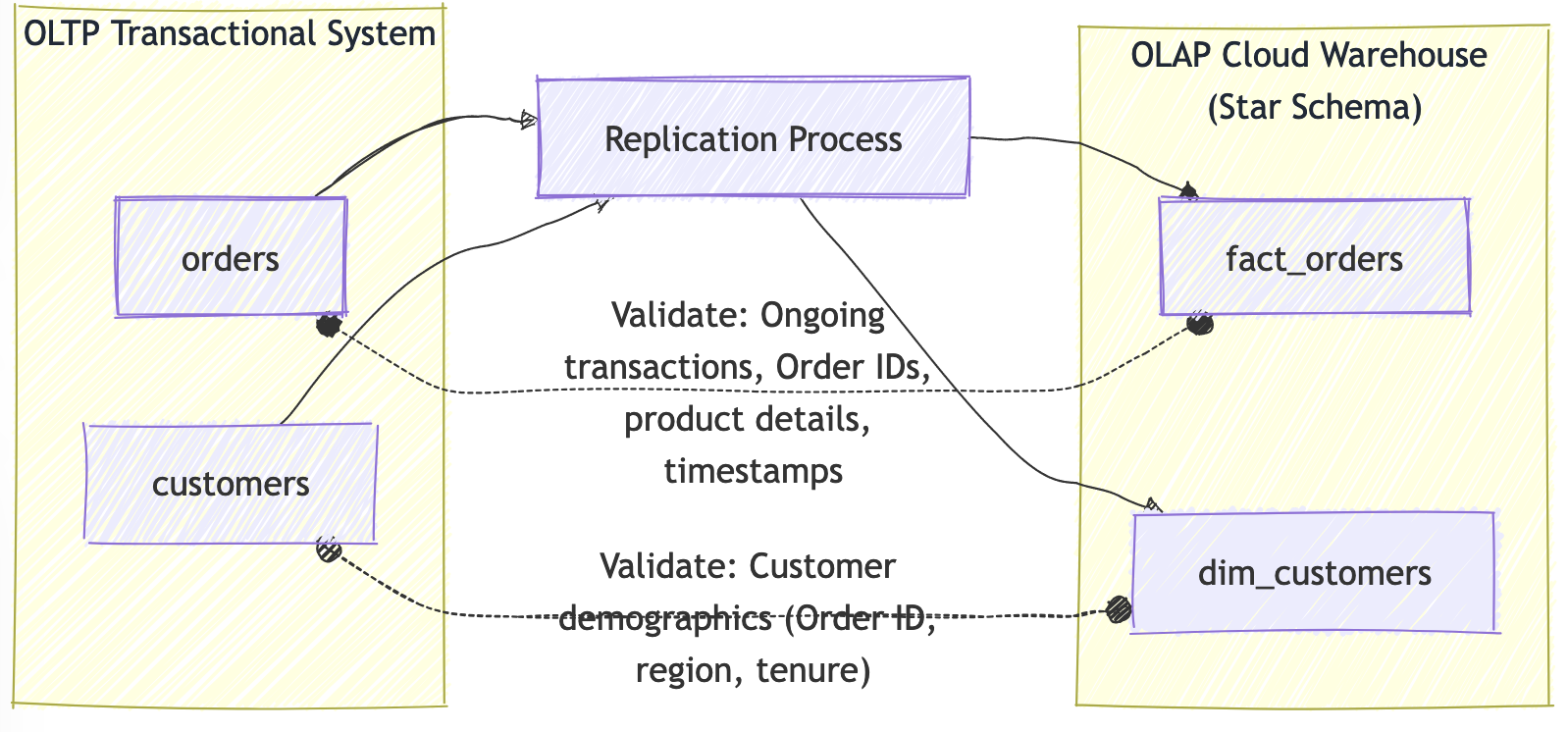
The team can use the data diff feature to continuously monitor and compare replicated data, ensuring that all historical and new transactions are accurately reflected in the cloud warehouse. This test ensures that ongoing replication remains intact, detecting issues like missing records or timestamp mismatches in near real time.
The Common Challenge
OpenMetadata’s Data Quality framework provides specifications that ensure that tables are complete, accurate, consistent, and fresh when compared to themselves or a user-defined parameter. While this covers many use cases, there are many cases where a data stakeholder might want to compare a table to another. This can be useful as either (1) propagating the data quality specification of one table to another or (2) serve as a proxy for validating any process that handles the data of one or both of the tables.
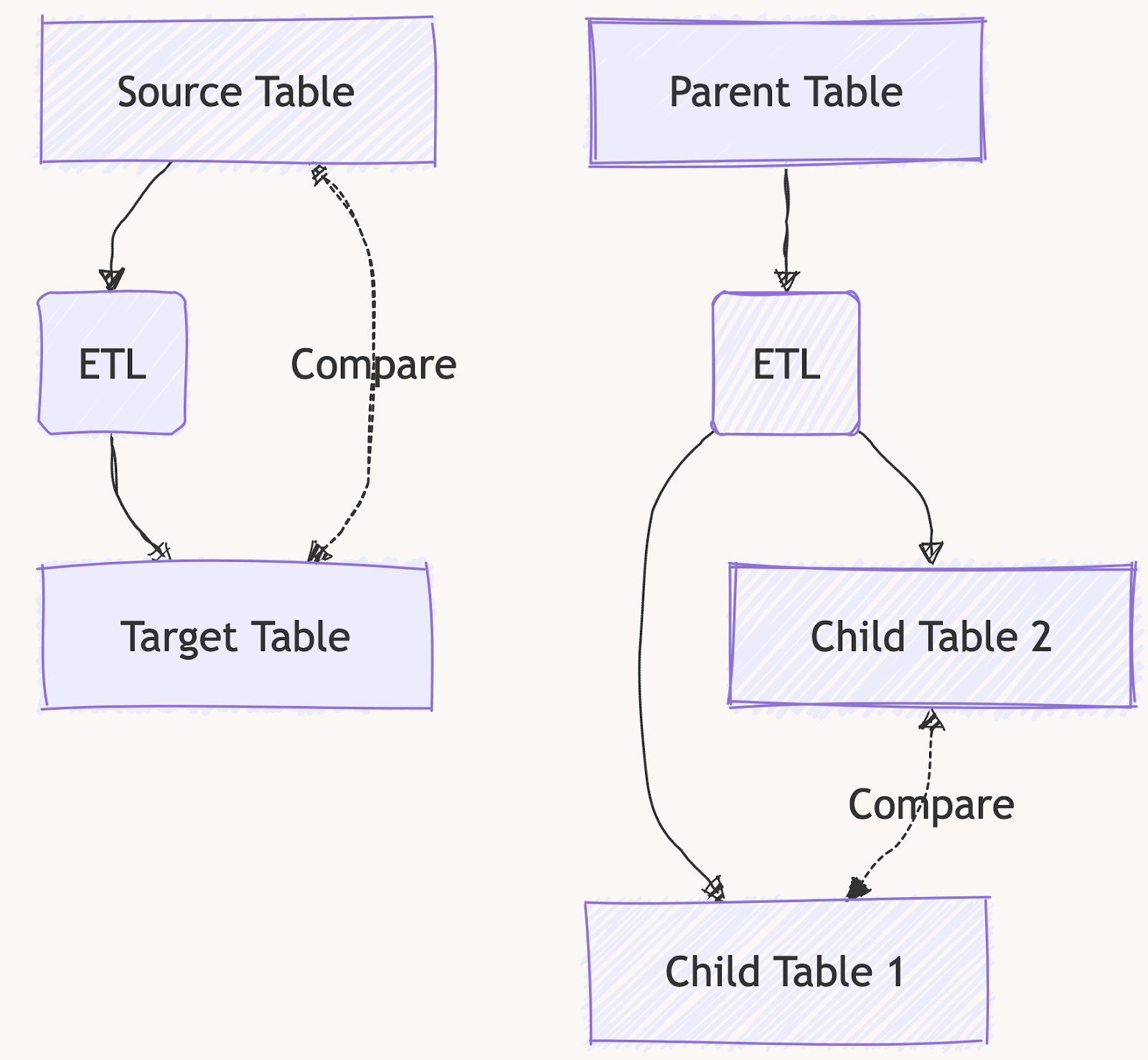
Introducing Data Diff in OpenMetadata
OpenMetadata introduces a new "data diff" feature, enabling users to compare tables and validate data integrity across different scenarios, services, and processes. This feature adds powerful capabilities to the data quality framework by allowing cross-table comparisons beyond the current self-referencing tests. This will enable all the data teams in the retail e-commerce scenarios to define test cases that fulfill the specifications outlined in our scenarios without owning any of the underlying assets!
The data diff test allows users to compare two tables, ensuring that data is transferred or transformed without errors. This can be incredibly useful for detecting discrepancies such as missing or duplicated rows during processes like ETL operations, feature generation for models, or database migrations.
This demo video introduces the data diff feature, highlighting the simplicity of setting up a table diff test. You can watch how to define table comparisons, check for differences, and analyze results directly within the platform. In Collate, we will also see a sample of the failed data for analysis.

Creating a table diff test

Viewing data diff results
Compare Across Services
One key advantage of the data diff feature is its ability to compare tables across different services and environments. This gives teams the flexibility to validate data consistency even when working across multiple databases and architectures. An example can be comparing your OLTP application database to a Cloud Data Lake or OLAP database.
Advanced Usage: The Where Clause
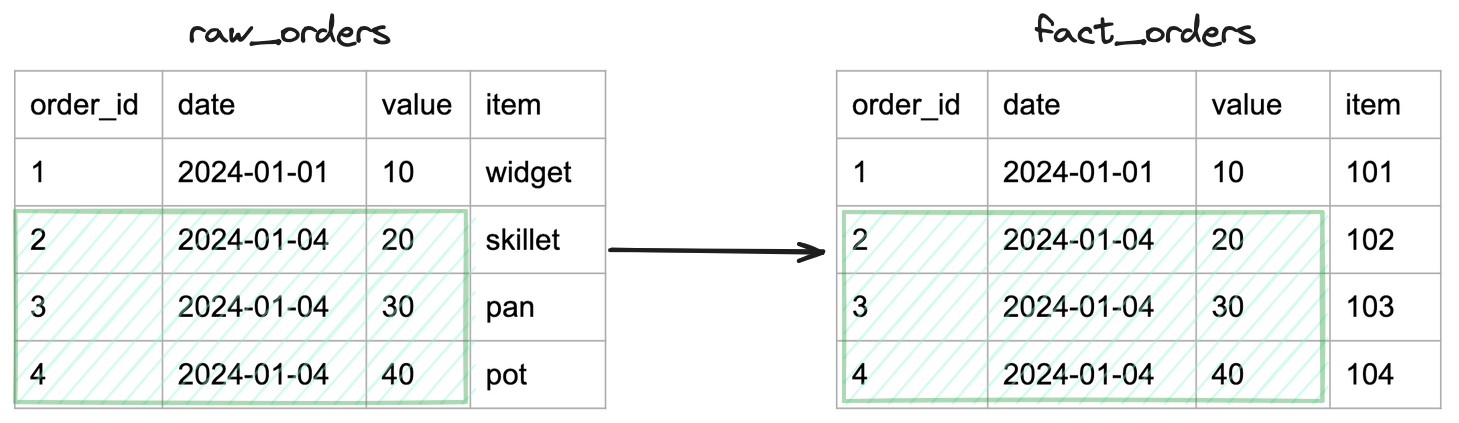
Users can leverage advanced filtering with the where clause for more fine-tuned control. This allows specific subsets of columns or rows to be compared, providing more granular insights. In the example below, the engineers owning the ETL transforming raw_orders into fact_orders only want to compare the last run (2024-01-04) and exclude the “item” column since it’s extracted as an id in the fact_orders table.
CLI Support
Data diff tests can be executed using the OpenMetadata CLI, allowing engineers to automate data quality validations as part of their CI/CD pipelines or custom workflows. This is particularly useful for teams with established automation practices or those running data quality tests outside the OpenMetadata platform. This is also useful in the context of CI. A data engineering team can use this to run the tests as part of their CI pipeline to assert if the ETL returns the same result as before the change (or not) or to compare the changes in a staging environment with the same table in production.
Alerts
By leveraging the existing alerting framework in OpenMetadata, users can configure automated alerts triggered when data mismatches are found between two tables during a data diff test. These alerts can be set up with customized conditions, ensuring that teams are notified only when critical data issues arise preventing alert fatigue. Notifications can be delivered via email, Slack, or any other preferred channel, integrating seamlessly into existing workflows.
For example, infrastructure teams running continuous replication can use alerts to track discrepancies between transactional data in production and the data warehouse, enabling immediate action when data drift is detected. This boosts confidence in the data pipeline and reduces the risk of errors making their way into production or business-critical reports.
Closing Remarks
Adding the new data Diff feature reflects OpenMetadata’s focus on delivering a unified metadata platform built to solve real-world challenges for data engineers and teams managing data at scale. By unifying discovery, data quality, and governance in one place, OpenMetadata simplifies how organizations approach data management.
The data diff feature is particularly crucial for data engineers. It adds powerful data validation capabilities that ensure data consistency across pipelines, systems, and environments. Whether you're moving data across environments or verifying complex ETL pipelines, this feature helps you catch issues early, giving you the confidence that your data transformations are accurate and reliable.
We invite you to join the OpenMetadata community on Slack and participate in shaping the future of the open-source platform. Whether you want to contribute ideas, report issues, or help build new features, the community is always open for collaboration. Let’s build the future of data management together! Join us on Slack.