Collate at Enterprise Scale: Supporting Millions of Data Assets & Relations


As companies of all sizes adopt Collate’s managed OpenMetadata service, we address questions from large organizations about the platform’s scalability, as not all systems can easily handle the growing demands of enterprise data platforms. This blog post explores how Collate can scale to support the world's largest enterprises.
The founders of Collate previously built Uber’s metadata platform Databook, where they comfortably managed data at Uber’s scale. Drawing from these past learnings and adding further architectural enhancements, we knew Collate was ready to meet even greater scalability challenges. To prove it, we have benchmarked the system’s capabilities for organizations operating at the extreme end of data scalability, exceeding even Uber’s requirements.
What follows are the testing benchmarks for OpenMetadata, which demonstrate high performance for millions of data assets and relations. For Collate’s managed OpenMetadata service, our global DevOps teams, deep familiarity with the code base, and deployment flexibility provide customers even higher standards for reliability and scalability.
Our Mission: Demonstrate OpenMetadata’s Enterprise Readiness
We embarked on a comprehensive benchmarking initiative to measure the scale and performance of OpenMetadata precisely. We deployed OpenMetadata in Amazon EKS, with Postgres 15 RDS and OpenSearch 2.19, on the following hardware configuration:
OpenSearch:
m7g.4xlarge.seaRDS Aurora Postgres:
db.r6gd.4xlargeCompute: 4x 16GB, with each node hosting a pod of the OpenMetadata server
Generating a Massive Dataset for Rigorous Testing
To simulate a large-scale enterprise environment, we used the Python faker library to generate a set of randomized assets. In total, our benchmark was conducted against 2 million assets and 5.8 million tags, all of which were meticulously indexed into OpenSearch to handle search requests. Breaking down the assets, we generated:
1.8 million tables, each with a random association of owners, domains, and tags (such as Tier and PII), and between 10 and 1000 columns.
50,000+ dashboards and dashboard data models
220,000 pipelines, with random lineage between tables.
This resulted in a metadata graph with over 15 million total relations among assets, tags, users, domains, tables, schemas, and other entities.
Benchmarking Methodology: Extreme Real-World Usage
We employed Locust, a robust benchmarking tool, to conduct our measurements. We focused on reproducing a typical user journey on the platform, interacting with the API to retrieve asset details for databases, database schemas, and tables, and updating both table descriptions and tags.
Using Locust, we simulated these user scenarios with 50, 500, and 1000 concurrent users, achieving peak loads of 1200 requests per second while measuring platform response times across all operations.
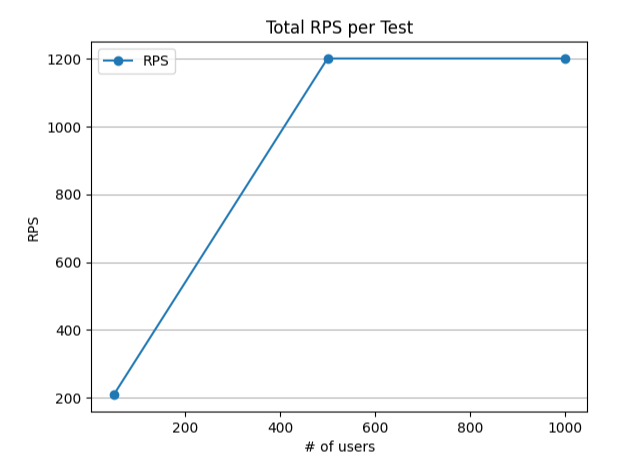
Total RPS per Test
Outstanding Performance Across Key APIs
As you can see from the results below, our API performance tests demonstrate OpenMetadata’s exceptional performance and scalability, with zero failed requests across all tested endpoints.
GET Databases, Database Schemas, and Tables
GET /api/v1/tables/{random_id}
GET /api/v1/databaseSchemas/{random_id}
GET /api/v1/databases/{random_id}
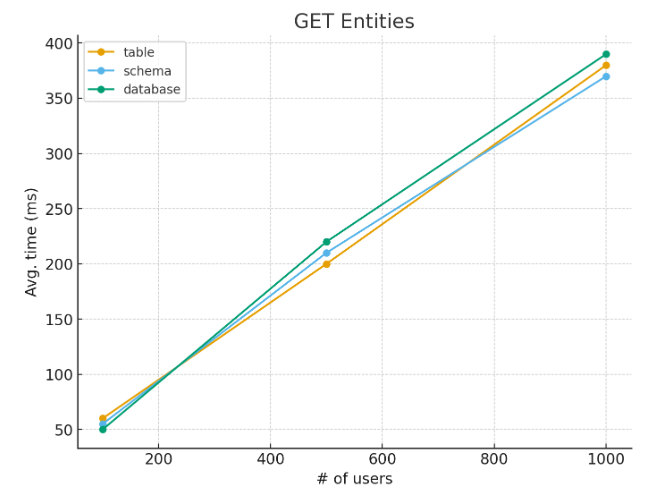
Average time for GET Entities
These results show that:
Even with 1,000 concurrent users, all requests respond in less than 400ms.
There’s no significant difference between the different asset types, even with 1.8 million tables.
PATCH Table
For this operation, we updated two pieces of constantly evolving metadata: descriptions and tags. To simulate a realistic scenario, each operation was done on a random table:
PATCH /api/v1/tables/{random_id}
[{
"op": "replace",
"path": "/description",
"value": "<p>Performance test description update</p>"
}]
and
[{
"op": "add",
"path": "/tags/0",
"value": {
"tagFQN": "PII.Sensitive",
"labelType": "Manual",
"state": "Confirmed",
"source": "Classification"
}
}]
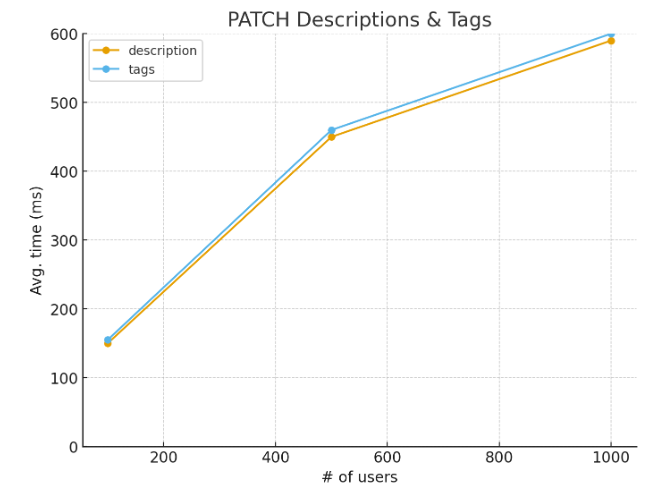
Average time for PATCH Descriptions & Tags
These results show that:
Even with 1,000 concurrent users, all requests respond in less than 600ms, with similar performance to read-only operations.
There’s no significant difference between updating a description or a tag, even when the platform holds 5.8 million tags overall.
Conclusion: Scaling with Your Ambitions
The numbers speak for themselves: even with 2 million entities, OpenMetadata’s system response times consistently fall under 400ms — 600ms for any read and write operations.
This comprehensive benchmarking demonstrates that OpenMetadata can scale comfortably to meet the needs of every company, regardless of its data volume. These benchmarks support the confidence of real-world users, such as Carrefour Brazil, the country’s largest retailer, and global fashion retailer Mango. In addition to establishing OpenMetadata’s scalability, these benchmarks also provide us with valuable insights to guide further improvements and enhancements.
For Collate customers of our managed OpenMetadata service, we provide enhanced reliability SLAs, deployment flexibility, and white-glove support. Coupled with additional differentiated features and the deep industry experience of our leadership team, we partner with our customers for our shared success. Contact us for more information on how we can help you get started on your data journey for AI-powered discovery, observability, and governance.