Announcing Collate 1.5


Collate, the creators of OpenMetadata—the fastest growing open source project for unified data discovery, observability, and governance—delivers more capabilities for data quality and insights in its latest version 1.5 release. New Collate features include anomaly detection AI, a new data quality dashboard, and freshness tests. In addition, Collate 1.5 contains the latest release of open source OpenMetadata 1.5, with capabilities like data diff tests, API metadata assets, domains RBAC, and new connectors.
Collate has seen incredible growth across Fortune 500 enterprises and data-native startups, with customers like Mango, Niche, and MBCP Bank using our platform to transform how their data teams work. You can use the new Collate 1.5 release for your production workloads by signing up for our free service tier or trying it out with demo data in our live sandbox.
And now, to the release highlights!
New Data Quality Dashboard
Losing trust in your data hurts credibility and productivity, and Collate tackles this problem by allowing both technical and non-technical users to collaborate on creating data quality tests directly from the UI. The new data quality dashboard organizes tests into different groups, making it easier to understand the data quality coverage of your tables and the potential impact of each test failure.
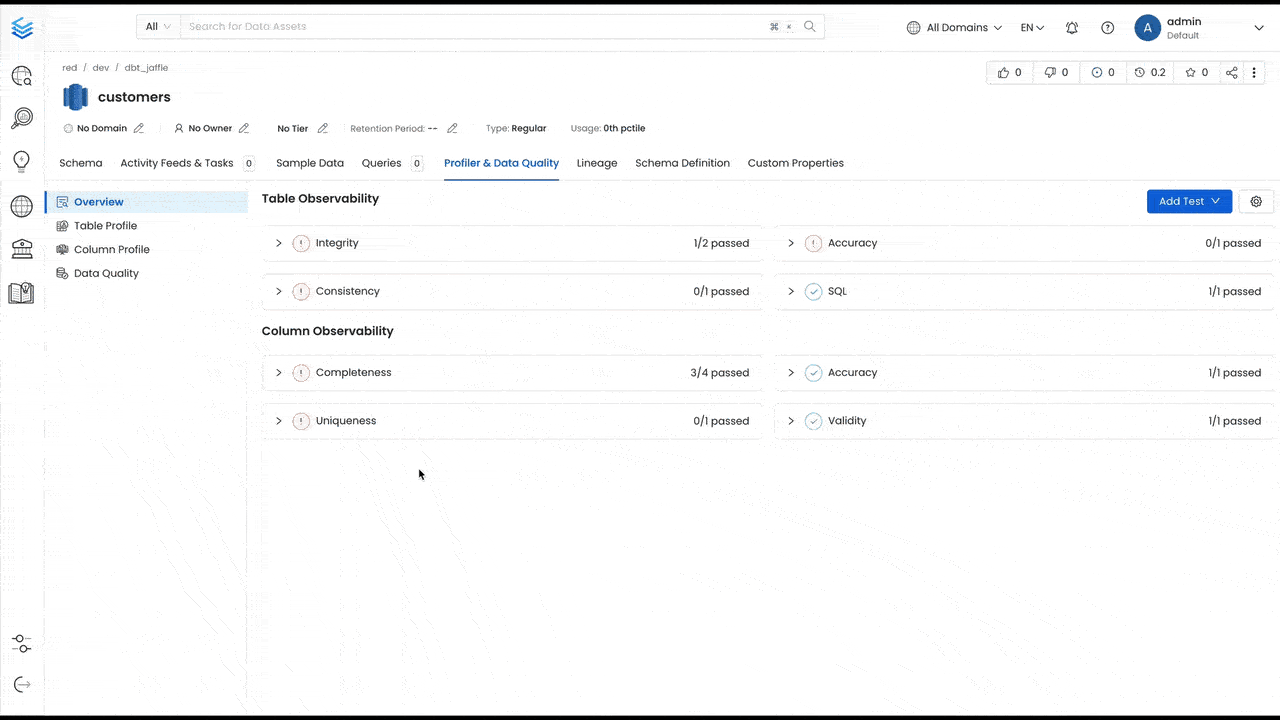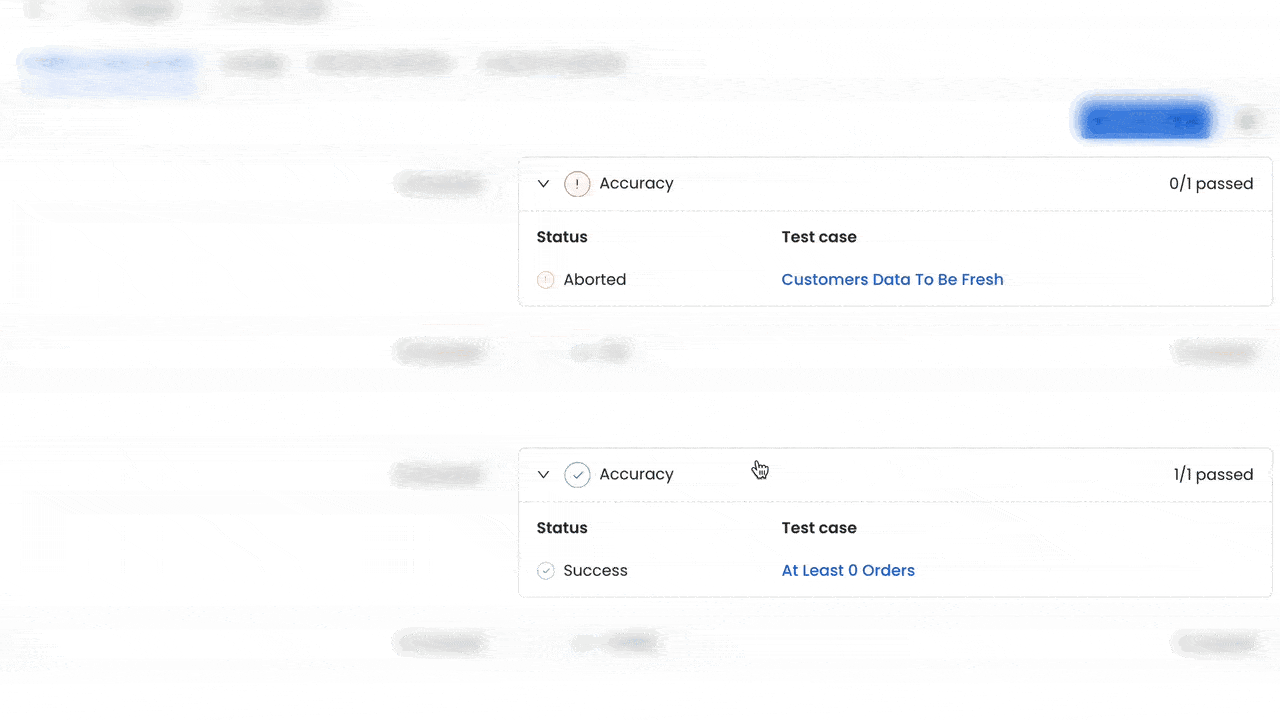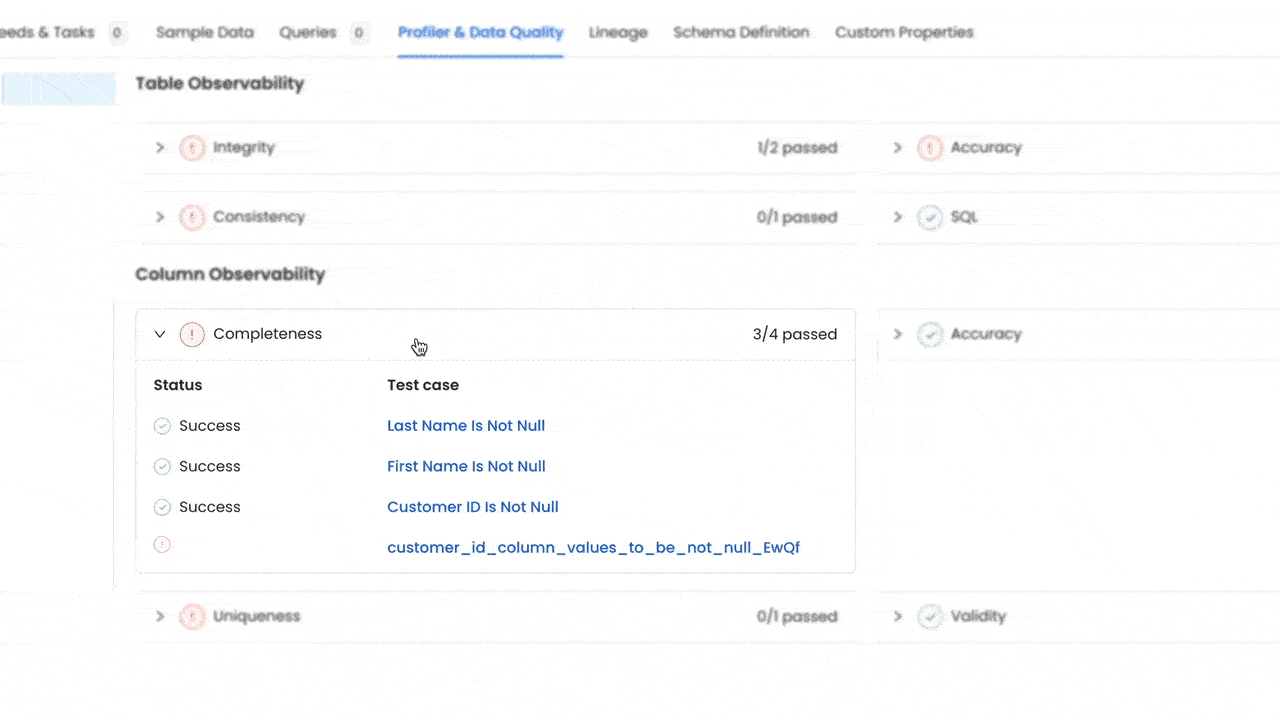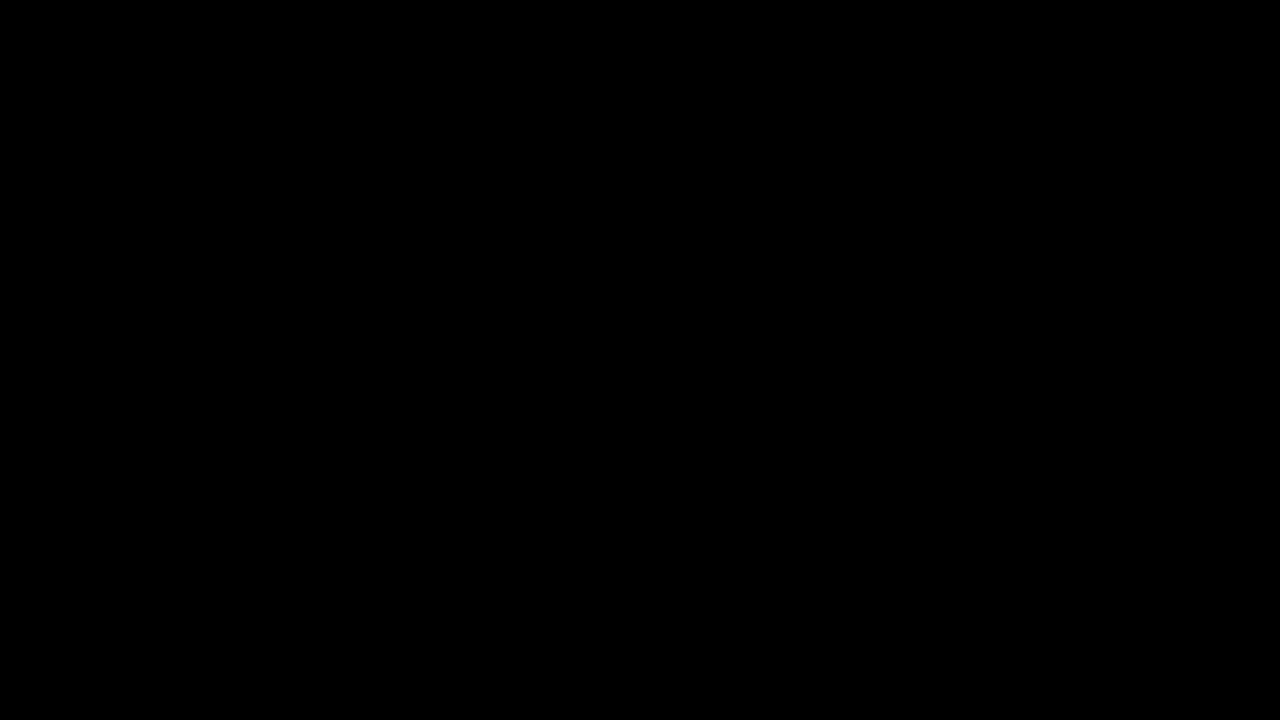
The dashboard and tests make it easier to ensure the quality of your data across different dimensions:
Integrity: Validate data to ensure it remains correct throughout transformation processes, such as checking the number of rows or seeing if a critical column is still present.
Accuracy: Guarantee data represents reality and is a trustworthy source of information—for example, data freshness or ensuring that the number of orders stays above 0.
Completeness: Check if essential data is missing.
Uniqueness: Validate records do not appear more than once.
Validity: Ensure data follows company business rules, such as by creating regular expressions to check emails or phone numbers.
Consistency: Ensure different representations of the same data match each other across different tables.
SQL: Run business rules and technical validations that are written using custom SQL queries.
By lowering the entry barrier to implementing data quality, more data practitioners can contribute their technical understanding and business knowledge to ensure the shape, structure, and reliability of important data. These shared responsibility and collaboration workflows help bring data teams together to reduce friction and increase productivity. In addition, Collate goes beyond creating tests to make metadata more actionable, with observability alerts and the Incident Manager help bring your teams together to resolve any issues.
Anomaly Detection AI for Data Quality
Collate provides a rich set of native capabilities for data quality, including no-code and SQL test cases, incident management, and alerting & notifications. However, understanding your data's behavior can require knowledge of its business context or technical specifications that data practitioners may not have, and this only becomes more challenging as data evolves.
We’re excited to introduce our new anomaly detection AI for data quality. The platform will learn the patterns of your data and dynamically assess spikes or drops out of bounds from the normal behavior of your data. Instead of updating your tests based on when your business grows, Collate will automatically adapt to the data, ensuring continuous and accurate monitoring of data quality.
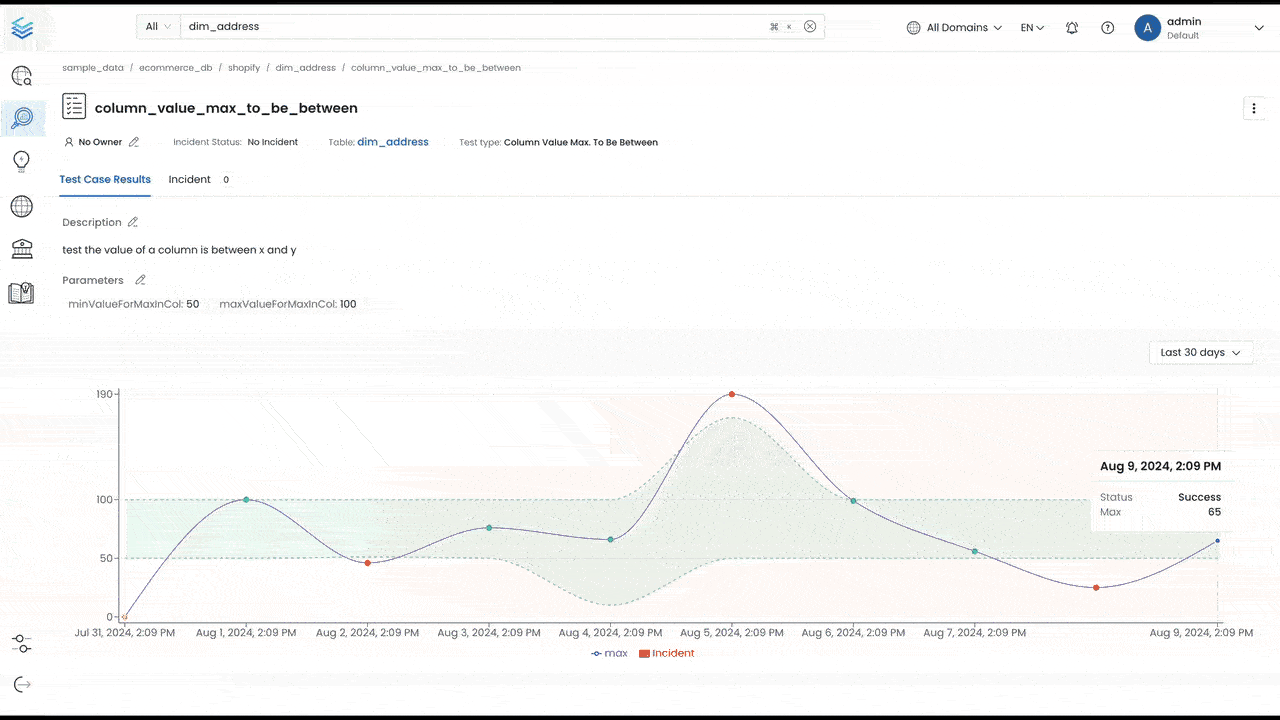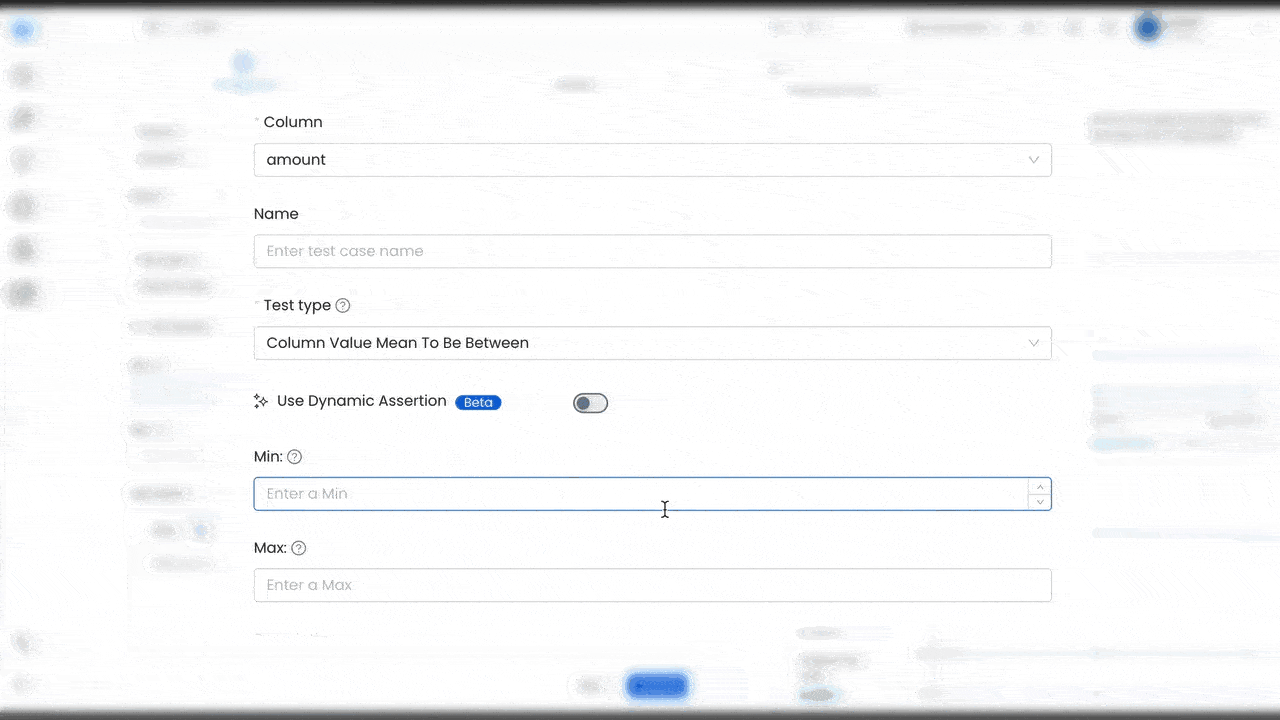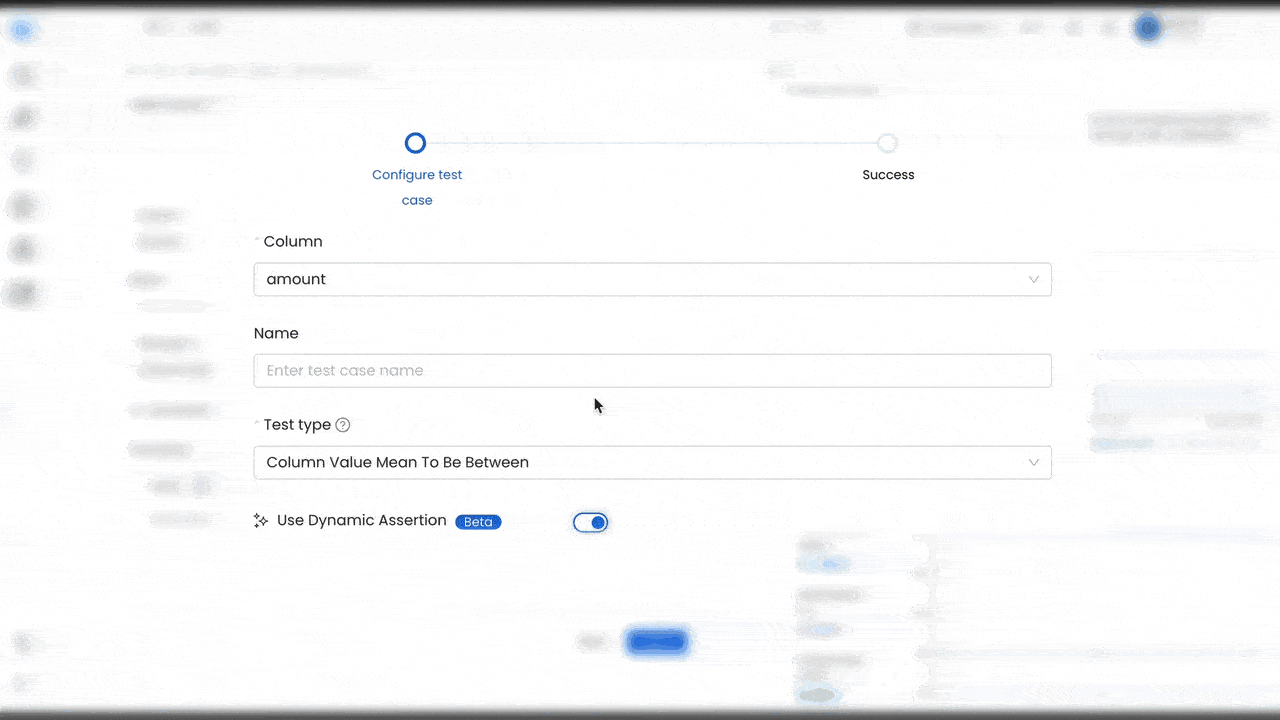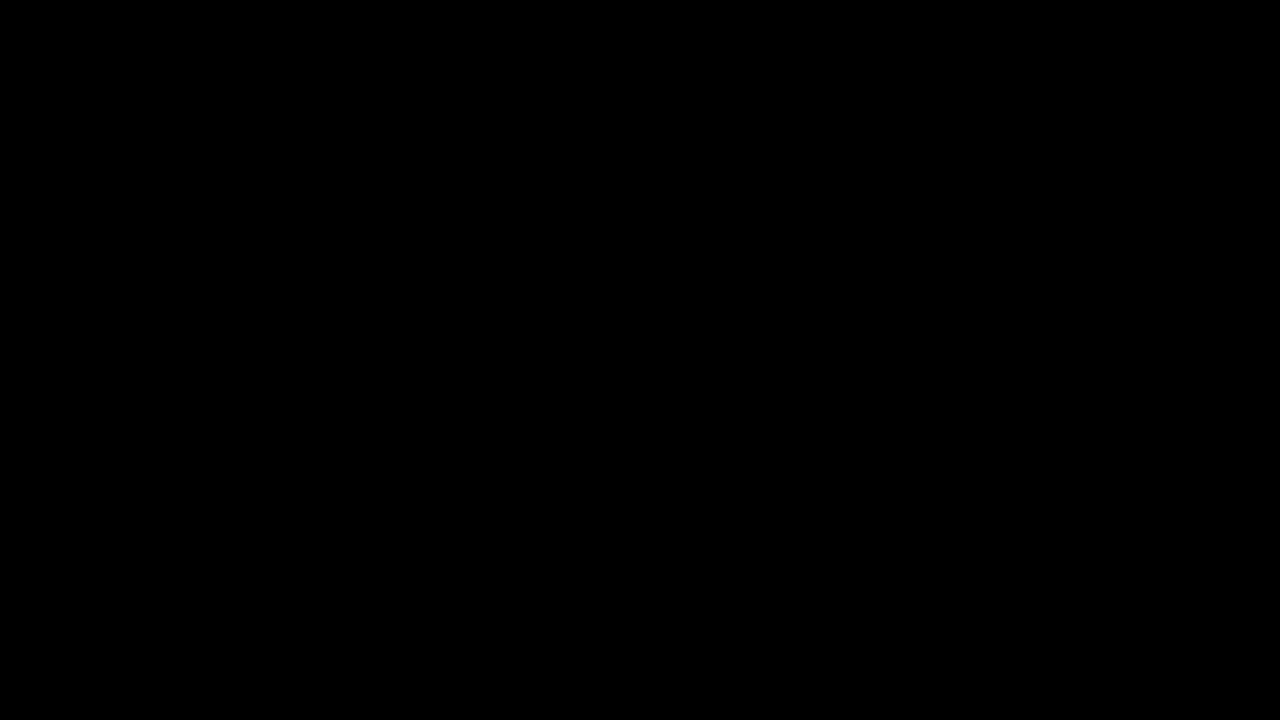
These new capabilities help improve data trust and reliability, while reducing manual work for data teams. Instead of having to define all the different scenarios, anomaly detection AI can develop the pattern matching, and evolve it over time with changing data trends. This helps to reduce business risk from unreliable data, improve data team productivity, while scaling with the needs of the organization.
Data Freshness Test
Working with stale data can lead to bad decision making and business risk. With the new freshness data quality test, you can validate that the data comes from a defined time window. For example, if data arrives late due to an integration issue or scheduling problem, this test can catch these issues and prevent the old data from causing problems downstream. Additionally, by combining these tests with lineage information and the Incident Manager, your team can quickly detect issues related to missing data or stuck pipelines.

Customizable Data Insights
Collate recognizes that data insights are crucial for enhancing an organization's data culture, by using KPIs to track critical metrics such as documentation and ownership coverage. In version 1.5.0, users can now create their own custom insights dashboards, providing data governance teams and data leadership more visibility to drive initiatives and hold data teams accountable.
Default data insights dashboards have long been available in Collate, covering a wide range of KPIs, such as data asset growth rate, data usage reports, user activity, description coverage, and more. By creating visibility into these health metrics, leaders can drive data culture changes for every user on the data platform. These reports improve overall data hygiene and stewardship, though different teams may have different needs with different metrics. With these new customizable data insights dashboards, teams can tailor these reports for their specific requirements.
In future releases, we will expand the available data in the Data Insights to also include glossaries and data quality results, bringing the data even closer to your business.
OpenMetadata 1.5 Feature Summary
The Collate 1.5 release also includes all the new capabilities the OpenMetadata 1.5 release, including many additional data quality and quality of life improvements:
Data Diff Data Quality Tests
Domains RBAC & Subdomains
Data Asset Explore & Landing Page Widget
API as a Metadata Asset
New Data Connectors
And many others!
Check out the OpenMetadata 1.5 blog for all the details.
Backward Incompatible Changes
Multi Owners
OpenMetadata allows a single user or a team to be tagged as owners of any data assets. Release 1.5.0 allows users to tag multiple individual owners or a single team. This will allow organizations to add ownership to multiple individuals without necessarily needing to create a team around them like previously.
This is a backward incompatible change. If you are using APIs, please make sure the owner field is now changed to “owners”.
Import/Export Format
To support the multi-owner format, we have now changed how we export and import the CSV file in glossary, services, database, schema, table, etc. The new format will be user:userName;team:TeamName .
If you are importing an older file, please make this change.
Pydantic V2
The core of OpenMetadata are the JSON Schemas that define the metadata standard. These schemas are automatically translated into Java, Typescript, and Python code with Pydantic classes.
In this release, we have migrated the codebase from Pydantic V1 t
Data Insights
The Data Insights application is meant to give you a quick glance at your data’s state and allow you to take action based on the information you receive. To continue pursuing this objective, the application was completely refactored to allow customizability.
Part of this refactor was making Data Insights an internal application, no longer relying on an external pipeline. This means triggering Data Insights from the Python SDK will no longer be possible.
With this change, you will need to run a backfill on the Data Insights for the last couple of days since the Data Assets data changed.o Pydantic V2.
UI - New Explore Page
Explore page displays hierarchically organized data assets by grouping them into services > databases > schemas > tables/stored procedures . This helps users organically find the data asset they are looking for based on a known database or schema they were using. This is a new feature and changes the way the Explore page was built in previous releases.
Include DDL
During the Database Metadata ingestion, we can optionally pick up the DDL for both tables and views. During the metadata ingestion, we use the view DDLs to generate the View Lineage.
To reduce the processing time for out-of-the-box workflows, we are disabling the include DDL by default, which potentially led to long-running workflows.
Python SDK
The metadata insight command has been removed. Since the Data Insights application was moved to be an internal system application instead of relying on external pipelines the SDK command to run the pipeline was removed.
Connector Schema Changes
Several updates and enhancements to the JSON schema across various connectors in the latest release. These changes aim to improve security, configurability, and expand integration capabilities. Here’s a detailed breakdown of the updates:
KafkaConnect: Added
schemaRegistryTopicSuffixNameto enhance topic configuration flexibility for schema registries.GCS Datalake: Introduced the
bucketNamesfield, allowing users to specify targeted storage buckets within the Google Cloud Storage environment.OpenLineage: Added
saslConfigto enhance security by enabling SASL (Simple Authentication and Security Layer) configuration.Salesforce: Added
sslConfigto strengthen the security layer for Salesforce connections by supporting SSL.DeltaLake: Updated schema by moving
metastoreConnectionto a newly createdmetastoreConfig.json. Additionally, introducedconfigSourceto better define source configurations, with new support formetastoreConfigandstorageConfig.Iceberg RestCatalog: Removed
clientIdandclientSecretas mandatory fields, making the schema more flexible for different authentication methods.DBT Cloud Pipelines: Added as a new connector to support cloud-native data transformation workflows using DBT.
Looker: Expanded support to include connections using GitLab integration, offering more flexible version control.
Tableau: Enhanced support by adding capabilities for connecting with
TableauPublishedDataSourceandTableauEmbeddedDataSource, providing more granular control over data visualization and reporting.
What’s next after 1.5
The new Collate 1.5 version enhances the ongoing innovation of OpenMetadata for data discovery, observability, and governance. Take a look at the OpenMetadata roadmap to see the expanding capabilities to cover more of the data management lifecycle. To hear the latest, don’t miss the online monthly community meeting by signing up here.
Learn More
Resources to learn more about Collate 1.5 and OpenMetadata 1.5 and to get started:
Read the How-to Guides
Watch our Demo videos
Join the Slack community
Sign up for Collate’s Free tier